 11 months ago
31
11 months ago
31
Virgin Media O2 (VMO2) is one of the leading telecom providers in the UK, with an impressive network of 46 million connections, encompassing broadband, mobile, TV, and home phone services. They are known for offering a large and reliable mobile network, coupled with a broadband infrastructure that delivers extremely fast internet speeds.
Three years ago, VMO2 set out to modernize its data platforms, moving away from legacy on-premises platforms into a unified data platform built on Google Cloud. This migration to cloud included multiple Hadoop-based systems, data warehouses, and operational data stores.
One of the key data platforms being migrated is the Netpulse system — a heavily used network data analytics and monitoring service that provides a 360-degree view of their customer's network and performance.
Netpulse combines several source systems together, but the core of the system is combining weblogs and location feeds in near real-time, using anonymized data to help ensure compliance with GDPR and other data privacy policies. Individually, both weblogs and location feed datasets hold substantial value for both network and customer analytics. Fusing these datasets provides a unified perspective with big potential, boosting VMO2’s ability to optimize network performance, enhance customer experiences, and swiftly address operational challenges that may arise. In essence, this enrichment represents a pivotal step towards a more informed and responsive network ecosystem, driving superior outcomes for both VMO2 and its customers.
In short, our team was eager to move to a cloud-based near real-time/real-time system to improve the accuracy, scalability, resilience and reliability of the Netpulse system. But first we had to find the optimal service, based on our requirements for high performance.
Scalability and latency challenges with on-prem Hadoop
VMO2’s existing on-premises Hadoop clusters were struggling to keep up with continuously increasing data volumes. While Hadoop captured both weblogs and location feeds at current volumes, real-time analytics on these feeds was impossible due to the challenges highlighted below. Further, the system lacked disaster recovery capabilities. Outages on the platform led to extended periods of data unavailability, impacting downstream analytics usage.
Overall the on-premises infrastructure had several challenges:
- Lack of scalability
- Capacity limits
- Expensive upgrades
- Software licensing costs
- Data center expansion constraints
Sizing the system
Before selecting a solution, we needed to understand the scope of the existing system, and our performance requirements.
Weblogs reports the web-traffic activities of VMO2’s mobile customers, encompassing interactions at both Layer 4 and Layer 7. It’s a voluminous dataset that generates approximately 2.5 TB every day; during peak hours, there are 1.5 billion records read and joined with another dataset. Another application, Mobility Management Entity (MME), generates control-plane data, providing real-time insights into the geographical whereabouts of VMO2’s mobile customers. MME generates another 2.1 TB of data daily and peaks at 900 million writes per hour. For our use case, we needed to process all incoming weblogs records while joining them with MME data, and store new MME records for quick lookup.
Looking at the peak hourly numbers, we determined that our system would need to support:
- 1.5 billion records read from weblogs, or 420,000 records read per second
- 900 million records written from MME, or 250,000 records written per second
That meant that at peak, the system would need to support about 670,000 operations per second. Further, for headroom, we wanted to size up to support 750,000 operations per second!
And while Netpulse needs to be able to perform near-real-time data transformation, it also performs lookups for MME data that is up to 10 hours old (after which the MME records expire). Only a subset of each MME record needed to be stored, amounting to 100 bytes per record. It is important to note that this data going back to 10 hours consists of the same unique records that are occasionally updated, so the overall storage size does not need to be 10 times the peak-hour size.
In other words, we needed to store less than 100 bytes from each MME record for a total of 900 million * 100 bytes, or 90 GB at peak, if all records were unique in that hour. So we safely set the max storage requirement to be double this number, i.e., 180 GB for 10 hours.
To meet these requirements, we determined that we needed a service that could function as both a key-value store and a fast lookup service. The system’s read-to-write ratio was going to be at least 2:1, with the potential of growing to 3:1. We also needed a high-throughput system that could scale and tolerate failure, as this service needed to be up and running 24/7 in production.
Choosing a solution
In short, we needed a data storage and processing solution for Netpulse that could meet the following requirements:
- Near real-time data transformation
- Ability to perform lookups for historical data
- High throughput
- Scalability
- Fault tolerance
- 24/7 availability
These stringent performance and availability requirements left us with several options for a managed database service. Ultimately we chose Memorystore for Redis because it can easily scale up to millions of operations per second with sub-millisecond latencies and provides us with a high SLA and also because Memorystore Redis:
- is a fast in-memory cache instead of using disk-based storage
- has easier-to-understand storage semantics, such as sorted sets
- scales to 100,000 requests per second for small (less than 1KB) reads and writes on a single Redis node
- was familiar to VMO2 teams
Further, once the data is enriched, it needs to be stored in an analytical store for further analysis. We chose BigQuery to power analytics on this and other datasets. Similarly, we chose
Dataflow for data transformation because it can handle data in real-time and scale to meet demand. Additionally, we had already standardized on Dataflow for ad-hoc data processing outside of BigQuery.
Proving scale with Memorystore for Redis
In terms of scale, storing processed data into a data warehouse like BigQuery was never a challenge; neither was data processing itself with Dataflow, even at massive scale. However, doing a fast lookup while incoming data was being processed was a huge challenge and something that we wanted to prove out before settling on an architecture.
We started with a single-node Redis instance and gradually added more memory, to get a sense of max writes for a given amount of memory.
We used Redis pipelining to batch requests together for both reads and writes. Redis pipeline was a necessity in this use case as the data sizes to be written and read were small, sending such small amounts of data over network would have meant that we had poor per record latency and poor overall throughput as well - due to network round trip associated with each redis command.
As the record size was less than 100 bytes, after various tests, we settled on 10,000 as pipeline size — giving us about 1 MB of data to send to Redis in one go.
Number of ZADDcommands handled
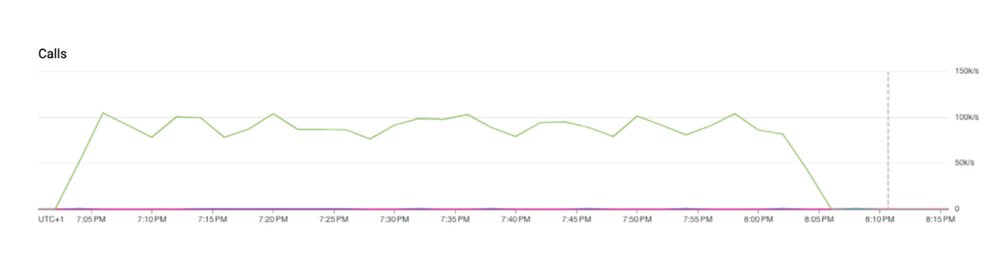
Where ZADD is shown in green above
Memory usage on the primary instance

Where pink is the instance memory and blue is the memory usage
Our testing revealed that 64 GB was the ideal Redis instance size because it could service 100,000-110,000 writes per second with spare capacity.
Once we had this information, we knew that to support 250,000 writes per second, we would need at least three Memorystore for Redis instances, each with a primary node (and read replica nodes to support reads).
Next, we tested the system's performance under concurrent read and write operations. This helped us determine the number of nodes required to support 500,000 reads and 250,000 writes per second.
ZREVRANGEcalls on two read replicas

Where blue lines are read ZREVRANGE commands fired on 2 read replicas.
A Memorystore for Redis instance with two read replicas was able to easily handle 200,000 read requests per second per node, for a total of 400,000 read requests per second.
After performance testing, we determined that we needed three Redis instances for production, each with one primary for writes and two read replicas for reads. Consistent hashing was used to shard writes across the three instances. This infrastructure could easily handle 300,000 writes and 1.2 million reads per second, which would be sufficient headroom for the use case. If we were to calculate per record latency for this batched workload, we will get a latency of under 100 microseconds.
The total number of nodes we needed for this use case was nine, across three Redis instances, each with one primary and three read replicas.
- 100,000 writes per second per primary x 3 = 300,000 writes per second
- 200,000 reads per second per replica x 6 = 1.2 million reads per second
You can find a variant of the detailed PoC to prove this architecture on github.
What came next - Memorystore for Redis Cluster
The architecture with Memorystore for Redis instance discussed above only allowed one primary write node with multiple read replicas, leading us to the aforementioned design using consistent hashing to achieve the required throughput.
We also tested Memorystore for Redis Cluster before its recent General Availability launch, following the methodology we used for our original design, and testing the infrastructure for an hour’s worth of sustained write and read load. We tested with different shard numbers and finally settled on 20 shards for the Memorystore for Redis Cluster instance, providing us 260+ GB of RAM — and significantly more performance than the sharded architecture. (In the previous design, we needed three 64GB Redis instances with one primary to support the write load of 192 GB of RAM available for writes and much more for reads.)
Further, with Memorystore Redis Cluster’s 99.99% SLA, we can easily provision multiple write nodes, called shards. This provides greater scalability and reliability, allowing the development team to focus on solving key business problems rather than managing Redis infrastructure and handling key sharding.
Testing Memorystore for Redis Cluster
We proceeded to test Memorystore for Redis Cluster extensively, to ensure the cluster could handle throughput at adequate per record latencies.
Memory usage on the cluster

We see memory usage go up during the test from about 2-3% to 68%.
Read and write calls on the cluster
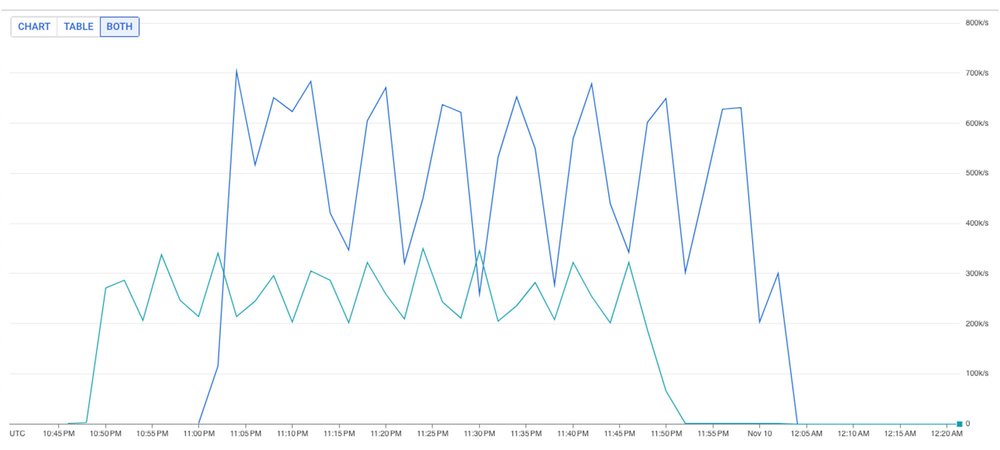
Where the blue line is read (ZREVRANGE) commands fired and the cyan line is write (ZADD) commands.
As represented above, we easily sustained a load of more than 250,000 writes and more than 500,000 reads for about an hour. During the tests, we could still see single command execution time of around 100 microseconds, while the memory usage was well under 70 percent. In other words, we didn’t push the cluster to its limit.
This Memorystore for Redis Cluster design gives us several advantages:
- Horizontal scaling - Redis Cluster performance scales linearly as we add nodes to the cluster, in contrast to standalone Redis, where vertical scaling offers diminishing returns on writes.
- Fully managed scaling - Instead of manually re-sharding keys as we add primaries, Memorystore for Redis Cluster automatically re-shards keys as we increase the number of primaries.
- Improved SLA from 99.9% to 99.99%.
- Significantly reduced costs AND improved performance - By converting from 9 x 64 GB nodes to 20 x 13 GB nodes, we are able to save about 66% in total costs AND see three times more performance.
The results with Memorystore for Redis Cluster have convinced us to use it in production now that it is GA.
Memorystore for Redis enables analytics at scale
With the migration to Memorystore, we’ve laid the foundation for seamless integration of weblogs and MME data in real-time. This critical development allows VMO2 to take advantage of a wide range of capabilities that come with this innovative solution, such as offloading to a fully-managed service, scalability, and a durable architecture complete with an SLA. At the same time, we are diligently training our team to use Memorystore's powerful features, which will unlock the potential for real-time analytics and lightning-fast data ingestion at an unprecedented scale and speed. We are also primed to use BigQuery along with Memorystore for several analytics use cases, such as network performance monitoring and smart metering.
To learn more about Memorystore for Redis Cluster, check out the documentationor head directly to the consoleto get started.