Storing and accessing data efficiently is a looming concern. Vector databases have emerged as a crucial technology in the field of data management and artificial intelligence applications, playing a significant role in modern computing. Unlike a traditional relational database, a vector database is designed to efficiently handle and retrieve vector embeddings of complex data types like images, videos, and audio. This makes them particularly suited for advanced search capabilities and AI-driven data analysis. But what are vector embeddings, what makes them so useful, and when should you use a vector database?
What is a vector database?
Classically, when people thought of “data” they thought of spreadsheets and charts. This is what we now call structured data, and it only makes up a very small fraction of the data we have access to these days. This type of data fits well in a traditional database. But all the unstructured data, things like images and blog posts where there are no neat tables of columns and rows, how can that best be stored?
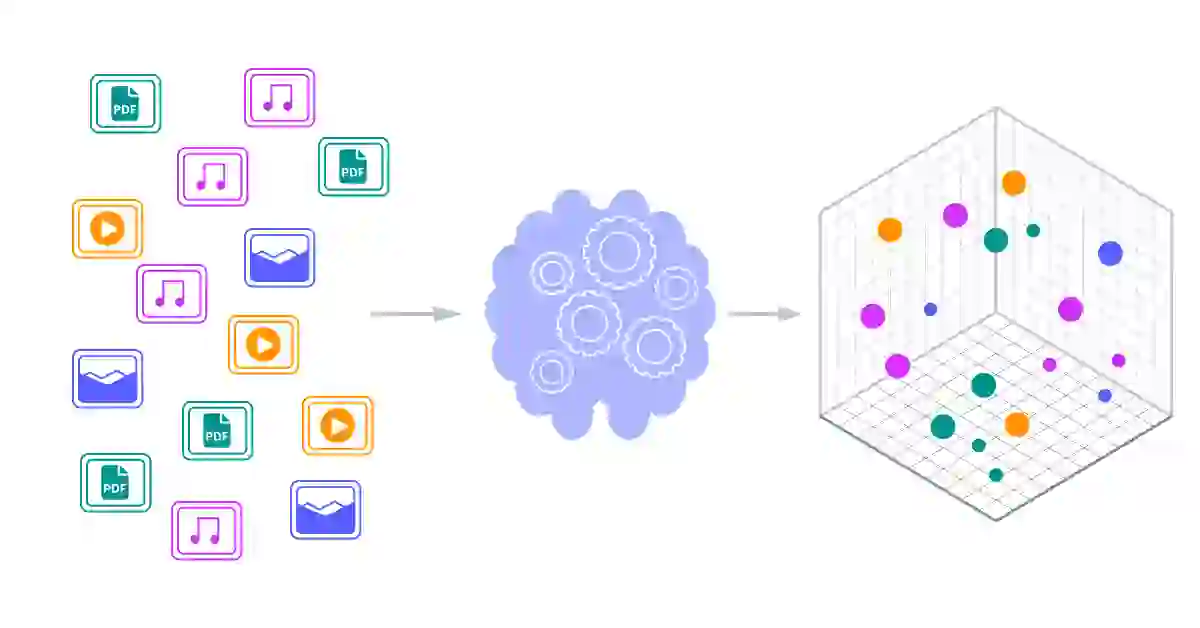
A vector database is a type of database designed for this very purpose: it not only stores unstructured data like images and blog posts but also the vector embeddings of these items. Through a process called vectorization we can transform complex, high-dimensional unstructured data into a lower-dimensional, numerical form that captures the essence of the data and then store each vector. These vector embeddings capture a huge amount of information about whatever piece of data they’re representing. The process of vectorization also normalizes your data, meaning that each vector you store will have the same dimensionality.
Their capabilities in handling large-scale datasets, providing fast and accurate vector search, and integrating with existing technologies make them a cornerstone for businesses and researchers aiming to leverage the power of AI.
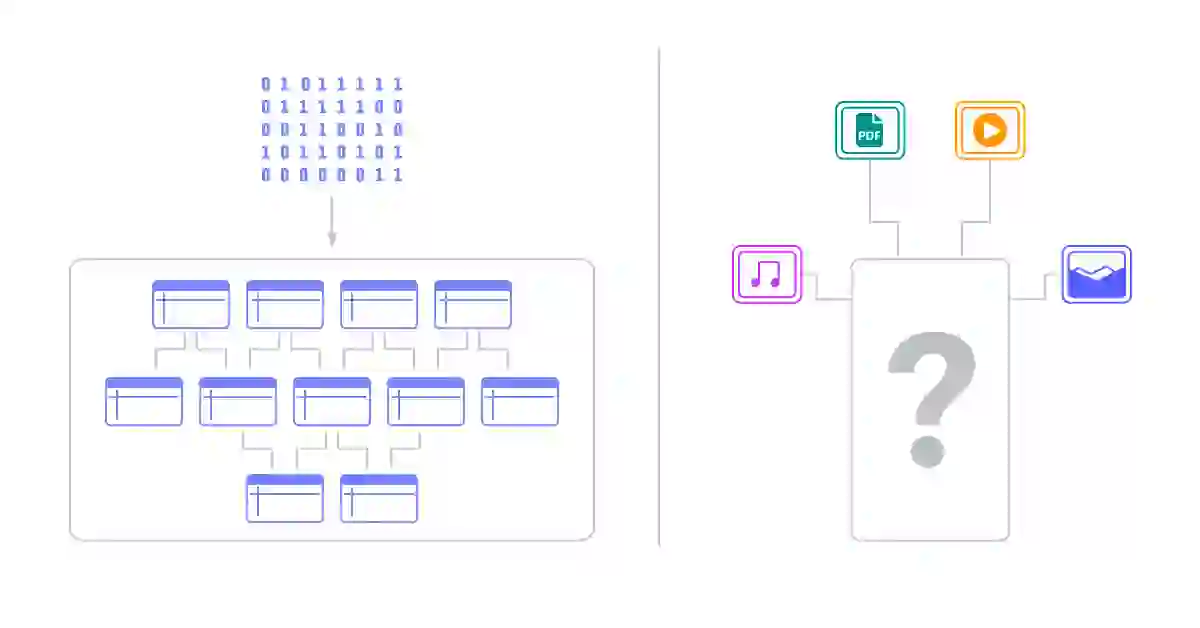
How Vector Databases Work
A vector database is designed to store vector data. But vector data isn’t something that can just be made up, it’s something that is generated via machine learning. There are plenty of machine learning models that convert unstructured data into vector embeddings; some are large language models to process text like descriptions and blog posts while others are vision models that create vector embeddings for images and videos.
Vector databases are optimized to store these vectors and to allow users to efficiently organize, search, and analyze this complex information in ways that traditional databases can’t. These databases use the embeddings to find the similarity between vectors, and in turn to power similarity search over the vectors being stored. There are different ways that we can calculate this similarity, such as Euclidean distance and cosine similarity. Each way of measuring that similarity captures something a little different, and which one works best for a specific problem will depend on the models and embeddings being used.
For instance the vector embeddings for an image could include information about colors used, if the image has soft versus hard lines throughout, if there are distinct shapes or figures, as well as the context of what those figures are doing. This type of contextual information that the embeddings capture are a result of the type of model used and the data it was trained on. This context dramatically improves search experiences for users. Imagine using an image of two people dancing to search, and getting back a top result of an image of two fish swimming beside each other because the colors of the pixels line up pretty closely. That’s probably not the most desirable search result. Using vector search instead can retrieve an image of two people dancing where the individual pixels might not match as closely but the overall image is a much closer match.

Each high dimensional vector in our getting started walkthrough stores 768 different numbers that each represent some piece of information about the data they’re describing, in this case the text of the descriptions of bicycles. A vector db uses different types of similarity measurements, that you can read more about here {vec sim 101 is also coming out}, to determine which vectors are closest to the one being searched.
Understanding Query Vectors in Vector Databases
Query vectors are a fundamental concept in the functionality of vector databases, serving as the cornerstone for the advanced search capabilities these systems offer. A query vector is essentially a vector representation of a search query, which could be derived from any form of unstructured data, such as a text description, an image, or an audio clip. This vector encapsulates the essence of the query in a numerical form, enabling the database to perform a similarity search against the stored vectors to find the most relevant results.
When a user submits a query to a vector database, the system first converts this query into its vector representation using the same vectorization process applied to the stored data. This ensures that the query and the database content are in the same dimensional space, making it possible to measure the similarity between the query vector and the database vectors. The database then utilizes algorithms like Euclidean distance or cosine similarity to identify and rank the stored vectors based on their closeness to the query vector, effectively finding the pieces of data that best match the user’s query.
The ability to convert queries into vectors and search for similar items makes vector databases incredibly powerful tools for a wide range of applications, from personalized recommendation systems to sophisticated content retrieval and NLP tasks. Query vectors allow these databases to understand and interpret the nuances and context of the search query, leading to more accurate and relevant search results compared to traditional keyword-based search methods.
Use Cases
Vector databases have gained prominence due to their pivotal role in supporting the development and deployment of AI applications. As these applications become more sophisticated, the need for efficient data storage and retrieval systems that can handle complex queries and large volumes of data has become critical. Vector databases, with their ability to efficiently store and manage high-dimensional vector data, are increasingly being recognized as an essential infrastructure component for AI-driven technologies.
Vector databases are instrumental in powering a wide range of applications across various industries due to their unique ability to manage and search high-dimensional data efficiently.
Key use cases include:
Recommendation Systems
Recommendation systems leverage vector databases to understand user preferences and content features, offering personalized suggestions in e-commerce, streaming services, and social media platforms.
Image and Video Retrieval: Vector databases enable fast and accurate search of visual content, crucial for digital libraries, stock image websites, and surveillance systems, by comparing the similarity between vectors representing images or video frames.
Natural Language Processing (NLP): Vector databases support NLP applications, such as semantic search, chatbots, and language translation services, by storing and searching text represented as vectors to capture contextual similarities.
Fraud Detection and Security: By analyzing behavioral patterns and detecting anomalies in real-time, vector databases help in identifying fraudulent transactions and potential security breaches, enhancing the safety of online systems.
Biometric Identification: The use of vector databases in biometric systems, such as facial recognition and fingerprint identification, allows for the rapid and precise matching of biometric data for security and authentication purposes.
The Future of Vector Databases
The future of vector databases is closely intertwined with the rapid advancements in generative AI, promising transformative changes in how data is managed, searched, and utilized. As generative AI technologies evolve, they are producing an ever-increasing volume of complex, high-dimensional data, from synthetic images to natural language constructs. Vector databases are poised to become even more critical in this context, serving as the backbone for efficiently storing and querying this data to fuel AI-driven innovations. The integration of vector databases with generative AI will enable more sophisticated and nuanced applications, ranging from creating highly personalized content in real-time to developing advanced simulations and predictive models across industries like healthcare, entertainment, and autonomous systems. This synergy is expected to push the boundaries of what’s possible, making data more accessible, interpretable, and actionable than ever before, and setting the stage for the next wave of breakthroughs in AI and data technology.
Additional Resources
To get started with a vector database, check out our getting started guide here and see just how easy it is to get vector embeddings stored and start doing vector search over them.

The post Vector Databases 101 appeared first on Redis.