 1 month ago
16
1 month ago
16
In today's fast-paced digital world, businesses are constantly seeking innovative ways to leverage cutting-edge technologies to gain a competitive edge. AI has emerged as a transformative force, empowering organizations to automate complex processes, gain valuable insights from data, and deliver exceptional customer experiences.
However, with the rapid adoption of AI comes a significant challenge: managing the associated cloud costs. As AI — and really cloud workloads in general — grow and become increasingly sophisticated, so do their associated costs and potential for overruns if organizations don’t plan their spend carefully.
These unexpected charges can arise from a variety of factors:
-
Human error and mismanagement: Misconfigurations in cloud services (e.g., accidentally enabling a higher-tiered service or changing scaling settings) can inadvertently drive up costs.
-
Unexpected workload changes: Spikes in traffic or usage, or changes in application behavior (e.g., marketing campaign or sudden change in user activity) can lead to unforeseen service charges.
-
Lack of proactive governance and cost transparency: Without a robust cloud FinOps framework, it's easy for cloud spending to spiral out of control, leading to significant financial overruns.
Organizations have an opportunity to proactively manage their cloud costs and avoid budget surprises. By implementing real-time cost monitoring and analysis, they can identify and address potential anomalies before they result in unexpected expenses. This approach empowers businesses to maintain financial control and support their growth objectives.
As one of the world’s leading cybersecurity organizations — serving more than 70,000 organizations in 150 countries — Palo Alto Networks must bring a level of vigilance and awareness to its digital business. Since it experiments often with new technologies and tools and deals with spikes in activity when threat actors mount an attack, the chances for anomalous spending run higher than most.
Recognizing the need of all its customers to effectively manage its cloud spend, Google Cloud launched the Cost Anomaly Detection as part of the Cost Management toolkit. It does not require any setup and automatically detects anomalies for your Google Cloud projects and empowers teams with details to alert and provide root-cause analysis. While Palo Alto Networks used this feature for a while and found it useful, it eventually realized the need for a customized solution. Due to stringent custom requirements, it wanted a service that could identify anomalies based on labels, such as applications or products that span across Google Cloud projects, and provide more control over anomaly variables that are detected and alerted to its teams. Creating a consistent experience across its multicloud environments was also a priority.
Palo Alto Networks’ purpose-built solution tackles cloud management and AI costs head-on, helping the organization to be proactive at scale. It is designed to enhance cost transparency by providing real-time alerts to product owners, so they can make informed decisions and act quickly. The solution also delivers automated insights at scale, freeing up valuable time for the team to focus on innovation.
By removing the worry of unexpected costs, Palo Alto Networks can now confidently embrace new cloud and AI workloads, accelerating its digital transformation journey.
Lifecycle of an anomaly
For Palo Alto Networks, anomalies are unexpected events or patterns that deviate from the norm. In a cloud environment, anomalies can indicate anything from a simple misconfiguration to a full-blown security breach. That's why it's critical to have a system in place to detect, analyze, and mitigate anomalies before they can cause significant damage.
This flowchart illustrates the typical lifecycle of an anomaly, broken down into three key stages:

Figure 1 - Lifecycle of an Anomaly
The following sections will take a deeper dive into how Palo Alto Networks used Google Cloud to build its custom AI-powered anomaly solution to address each of these stages.
1. Detection
The first step is to identify potential anomalies.Palo Alto Networks partnered with Google Cloud Consulting to train the ARIMA+ model with billing data from its applications using BigQuery ML (BQML). The team chose this model for its great results for time-series billing data, its ability to customize hyper parameters, and its overall effective cost of operation at scale.
The ARIMA+ model allowed Palo Alto Networks to generate a baseline spend with upper and lower bounds for its cost anomaly solution. The team also tuned the model using Palo Alto Networks’ historic billing data, enabling it to inherently understand factors like seasonality, common spikes and dips, migration patterns, and more. If the spend exceeds the upper bound created by the model, the team can then quantify the business cost impact (both percentage and dollar amount) to determine the severity of the alert to be investigated further.

Figure 2 - AI-Powered Cost Anomaly Solution Architecture on Google Cloud
Looker, Google Cloud’s business intelligence platform, serves as the foundation for custom data modeling and visualization, seamlessly integrating with Palo Alto Networks’ existing billing data infrastructure, which continuously streams into BigQuery multiple times a day. This eliminates the need for additional data pipelines, ensuring the team has the most up-to-date information for analysis.
BigQuery MLempowers Palo Alto Networks with robust capabilities for machine learning model training and inference. By leveraging BQML, the team can build and deploy sophisticated models directly within BigQuery, eliminating the complexities of managing separate machine learning environments. This streamlined approach accelerates the ability to detect and analyze cost anomalies in real time. In this case, Palo Alto Networks trained the ARIMA+ model on the last 13 months of billing data for specific applications on the Net Spend field to capture seasonality, spikes and dips, along with migration patterns and known spikes based on a custom calendar.
To enhance alerting and anomaly management processes, the team also utilizes Google Cloud Pub/Sub and Cloud Run functions. Pub/Sub facilitates the reliable and scalable delivery of anomaly notifications to relevant stakeholders. Cloud Run functions enable custom logic for processing these notifications, including intelligent grouping of similar anomalies to minimize alert fatigue and streamline investigations. This powerful combination allows Palo Alto Networks to respond swiftly and effectively to potential cost issues.
2. Notification and analysis
Once the anomaly is captured, the solution computes the business cost impact and routes alerts to the appropriate application teams through Slack for further investigation. To accelerate root-cause analysis, it synthesizes critical information through text and images to provide all the details about anomaly, pinpointing exactly when it occurred and which SKUs or resources are involved. Application teams can then further analyze this information and, with their application context, quickly arrive at a decision.
Here is an example of snapshot that captured an increased cost in BigQuery that started on July 30th:
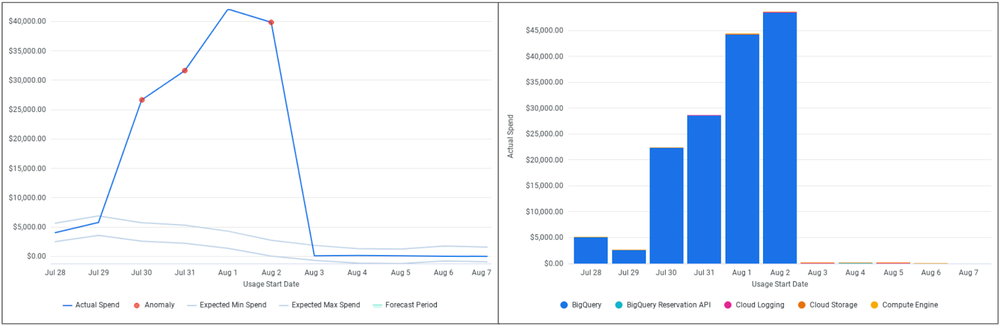
Figure 3 - Example of Anomaly Detected with Resource details
The cost anomaly solution automatically gathered all the information related to the flagged anomalies, such as Google Cloud project ID, data, environment, service names andSKUs, along with the cost impact. This data provided much of the necessary context for the application team to act quickly. Here is an example of the Slack alert:
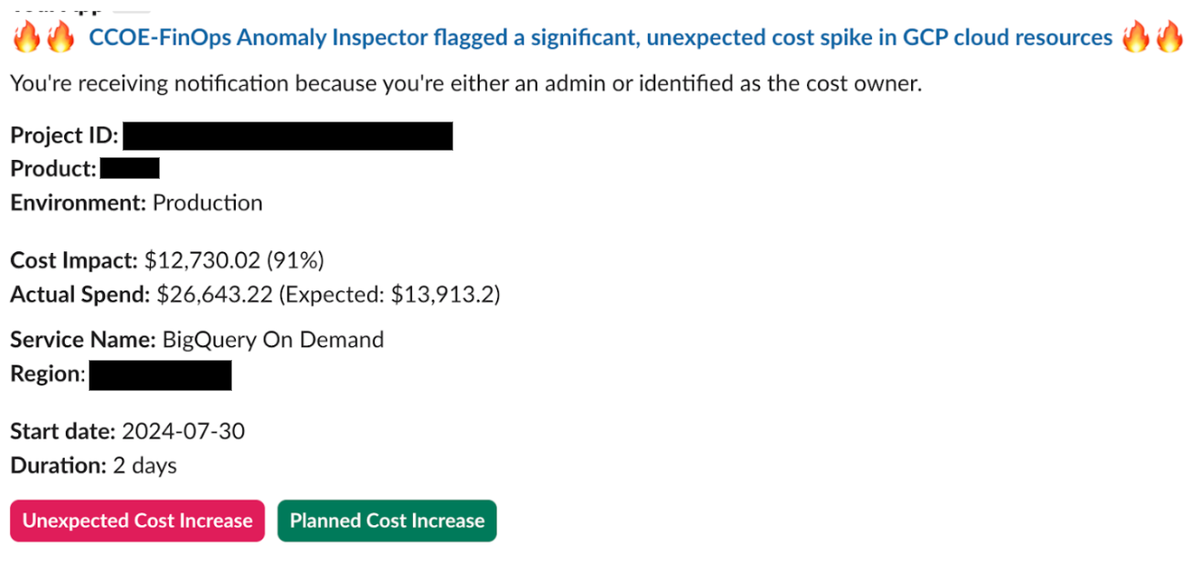
Figure 4 - Example of anomaly alert on Slack
3. Mitigation
Once the root cause is identified, it's time to take action to mitigate the anomaly. This may involve anything from making a simple configuration change to deploying a hotfix. In some cases, it may be necessary to escalate the issue and involve cross-functional teams.
In the provided example, a cloud hosted tenant encountered a substantial increase in data volume due to a configuration error. This misconfiguration led to unusually high BigQuery usage. As no default BigQuery reservation existed in the newly established region, the system defaulted to the on-demand pricing model, incurring higher costs.
To address this, the team procured 100 baseline slots with a 3-year commitment and implemented autoscaling to accommodate any future spikes without impacting performance. To prevent similar incidents, especially in new regions, a long-term cost governance policy was implemented at the organizational level.
Post incident, the cost anomaly solution generates a blameless post mortem document containing the highlights of the actions taken, the impact of collaboration, and the cost savings achieved through timely detection and mitigation. This document focuses on:
-
A detailed timeline of events: This list might include when a cost increase was captured, when the team was alerted, and the mitigation plan with short-term and long-term initiatives to prevent this in future.
-
Actions taken: This description includes details about anomaly detection, the analysis conducted by the application team, and mitigative actions taken.
-
Preventative strategy: This describes the short-term and long-term plan to avoid similar future incidents.
-
Cost impact and cost avoidance: These calculations include the overall cost incurred from the anomaly and estimate the additional cost if the issue had not been detected in a timely manner.
A formal communication is then sent out to the Palo Alto Networks application team, including leadership, for further visibility.
From its experience working at scale, Palo Alto Networks has learned to embrace the fact that anomalies are unavoidable in cloud environments. To manage them effectively, a well-defined lifecycle encompassing detection, analysis, and mitigation is crucial. Automated monitoring tools play a key role in identifying potential anomalies, while collaboration across teams is also essential for successful resolution. In particular, the team places huge emphasis on the importance of continuous improvement for optimizing the anomaly management process. For example, they established the reporting dashboard below for long-term continuous governance.

Figure 5 - Cost Anomaly Reporting Dashboard in Looker
By leveraging the power of AI and partnering with Google Cloud, Palo Alto Networks is enabling businesses to unlock the full potential of AI while ensuring responsible and sustainable cloud spending. With a proactive approach to cost anomaly management, organizations can confidently navigate the evolving landscape of AI, drive innovation, and achieve their strategic goals. Check out the public preview of Cost Anomaly Detection or reach out to Google Cloud Consulting for a customized solution.
We are extremely grateful to the entire team for partnering together to build this solution: Yaping Gu, Matt Orr, Andy Crutchfield, and Gina Huh.
Posted in