 8 months ago
45
8 months ago
45
Knowledge is power. Knowing who is responsible for specific areas and services is a vital skill that saves time and hassle. This can quickly become overwhelming and hard to manage in today’s complex microservice environments. Combining services and responsible teams increases transparency, simplifies the identification of the right people, enables automation, and saves time and money.
As always, work must be done before you can reap the rewards. This includes preparing the environment with the required metadata to provide the ownership information transparently and when needed. These efforts include:
- Extending entities with ownership metadata.
- Enriching ownership information with desired metadata.
- Ensuring ownership coverage in the environment.
- Automating incident triage via targeted remediation or notification tasks.
What to consider when adding ownership information
Introducing ownership information requires several simple steps and typically depends on the desired application. In any case, three building blocks are required to connect the right information to software artifacts.
- Linking team ownership with the specific service or component they own.
- Enriching team ownership information with desired metadata.
- Providing easy access to team ownership information.
The first challenge is the assignment of team ownerships to the appropriate entities. At first glance, this sounds easy: Team A takes care of component B. However, as software changes continuously due to new deployments and releases, so can responsibilities. Revisiting an environment to ensure the assignments are still correct is almost impossible when done manually. The automated extraction of ownership information, for example, from Kubernetes annotations, is therefore essential.
Secondly, knowing who is responsible is essential but not sufficient, especially if you want to automate your triage process. Essential metadata about team ownership helps in addressing the right team with the appriopriate responsibilities via the desired channels. As teams and their structure and metadata are often maintained in a dedicated database, such as Microsoft Entra ID (formerly Azure Active Directory) or ServiceNow. This information needs to be reusable, avoiding the need to maintain the same information twice and ensuring data is not out of sync.
Keeping ownership teams and their properties up to date is essential, as is having the right contact information available when needed.
Finally, the best information is still useless if users can’t retrieve it quickly when needed and use it accordingly. Be it a visual representation or an automated task in a workflow, easily resolving ownership information for services is where the full value becomes noticeable.
How to efficiently introduce team ownerships
Dynatrace provides different ways of associating team ownership with entities and adding desired team metadata, such as contact details, to your environments.
Import teams
It is necessary to get ownership team information into the system and keep it updated. Dynatrace offers several ways to ingest ownership team information. Besides supporting UI and API input for ownership teams, a dedicated workflow action for importing, storing, and updating ownership teams is available.
The import_teams workflow action can be used in either an on-demand or a regularly triggered workflow to get ownership team information and store it accordingly. As data sources can vary, the import_teams action supports different options. Besides the generic import option of accepting JSON objects in the ownership schema (find details on how to use the import teams workflow actions here), two often-used databases for storing and maintaining team information are available to you:
- Microsoft Entra (formerly Azure Active Directory)
- ServiceNow (sys_user_groups)
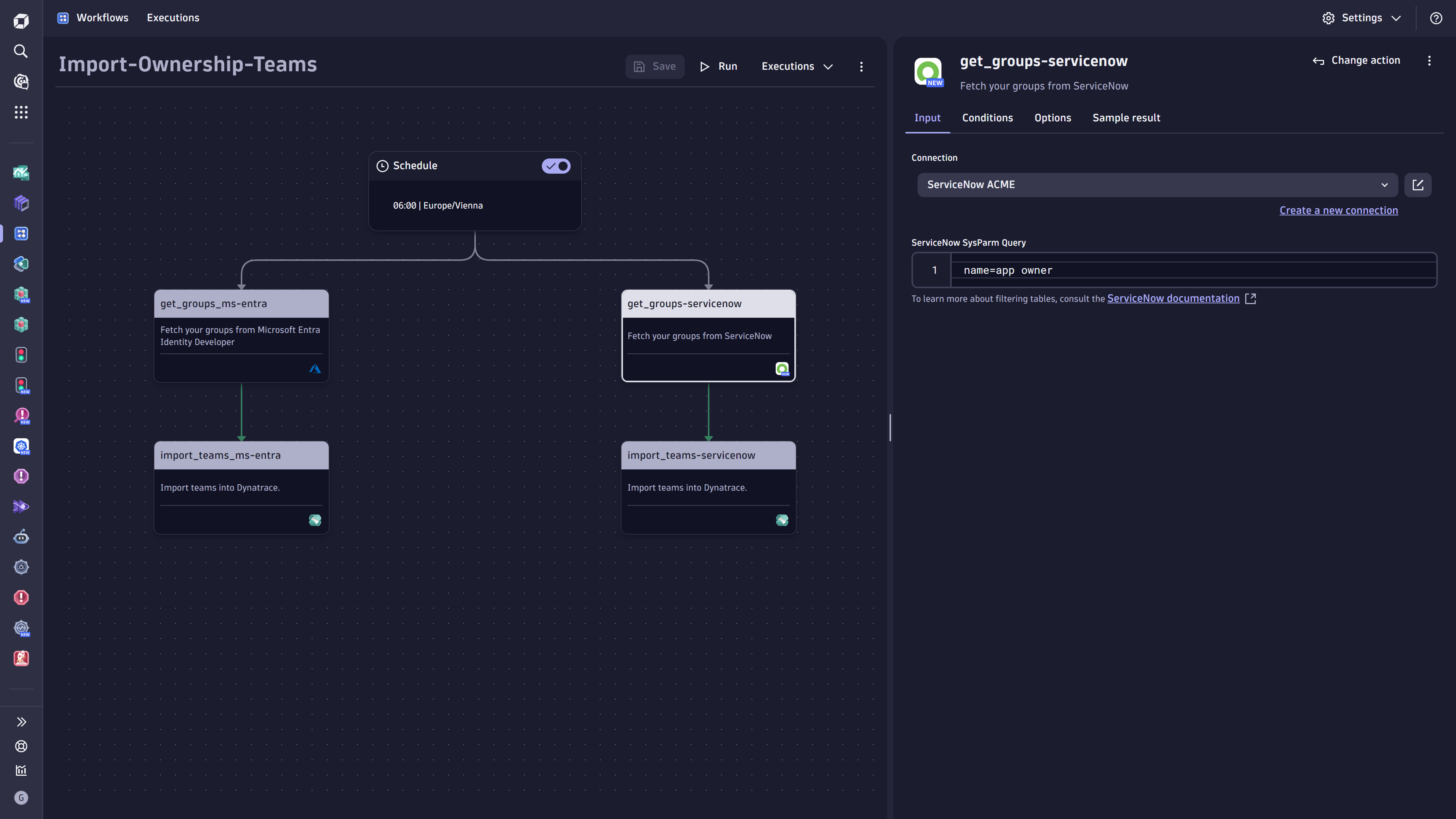 Figure 1. Dynatrace workflow showing two ownership team-import workflows for ServiceNow and Microsoft Entra ID
Figure 1. Dynatrace workflow showing two ownership team-import workflows for ServiceNow and Microsoft Entra IDThe ownership team information can be queried regularly from the databases, maintaining them as the source of truth for the team and its properties. A dedicated workflow allows automatic synchronization of the database information with Dynatrace and keeps the ownership team information up-to-date.
Dynatrace ownership functionality supports configuration-as-code via its proprietary Monaco (Monitoring as code) CLI or Terraform. An example via Monaco can be found in this public GitHub repository.
Assign teams to services
This correlation between people and software is crucial; if a problem occurs or a new security vulnerability is detected, it’s critical to quickly and easily know who is responsible and owns each specific software artifact.
As the ownership of certain components is highly dependent on the organization structure and possibly quite dynamic or heterogeneous, the linking is realized via key-value pairs added to the entities. This ensures flexibility in adding the ownership information when needed.
Since adding key-value pairs to entities is highly flexible, there are several ways of adding ownership metadata to an environment. However, to increase reliability, it’s recommended to add the ownership information depending on the environment characteristics. In cloud-native environments Kubernetes annotations or labels are recommended; these can be further used to propagate certain information within the software topology. Dedicated environment variables or custom properties are additional options to add ownership related metadata. More details on the supported ways of enriching your environment are described in Best practices for ownership information documentation.
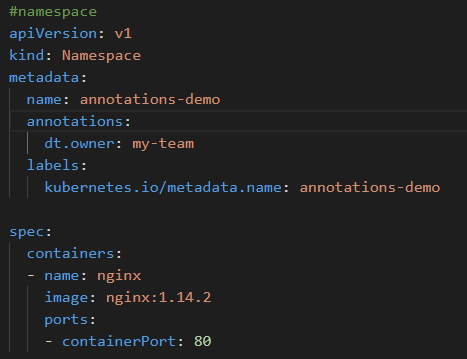 Figure 2. Example of a Namespace Definition with an ownership team assigned via annotations
Figure 2. Example of a Namespace Definition with an ownership team assigned via annotationsWhen adding ownership teams, the key must start with one of five customizable indicators to be recognized as ownership metadata. By default, Dynatrace supports dt.owner or owner as the key prefix, while the value needs to reflect the unique team identifier. This guarantees an unambiguous identification of the right owners per component. The team identifier can be set only when creating the ownership team for the first time, either through the previously explained ownership importer or manually via the web UI or API.
If certain naming conventions or key-value pairs are already used to tag services or apps with responsible teams, it’s possible to reuse the same keys easily. For example, if team:myTeamName is already used to mark selected components, then team can be added as a supported key. Dynatrace will automatically recognize the existing tags as ownership metadata. Otherwise, it’s recommended that you reuse the default key prefix to stay consistent throughout the environment.
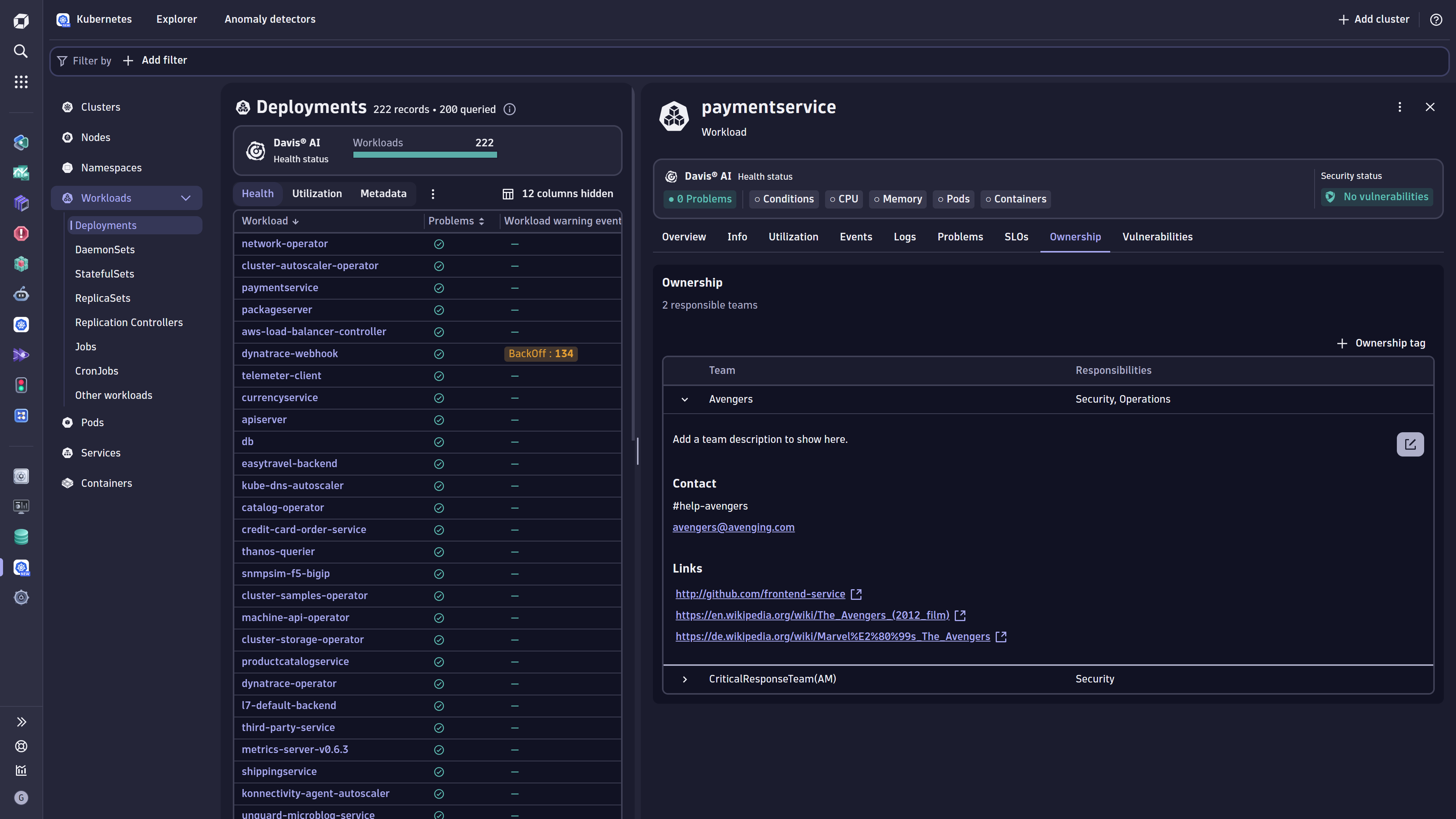 Figure 3. Illustration how Dynatrace automatically adds ownership team information of a work load after successful ingest and assignment
Figure 3. Illustration how Dynatrace automatically adds ownership team information of a work load after successful ingest and assignmentTo keep an overview of which areas in an environment are already covered and where there might be potential blind spots, ownership information (or the lack thereof) can be easily visualized in notebooks and dashboards. The dashboard shown in figure 4 below can be found in the publicly accessible Github Repository:
https://github.com/dynatrace-perfclinics/platform-engineering-demo/blob/main/dynatraceassets/dashboards/team-ownership-dashboard.json
The dashboard serves as an example and likely needs to be adapted to your specific user needs.
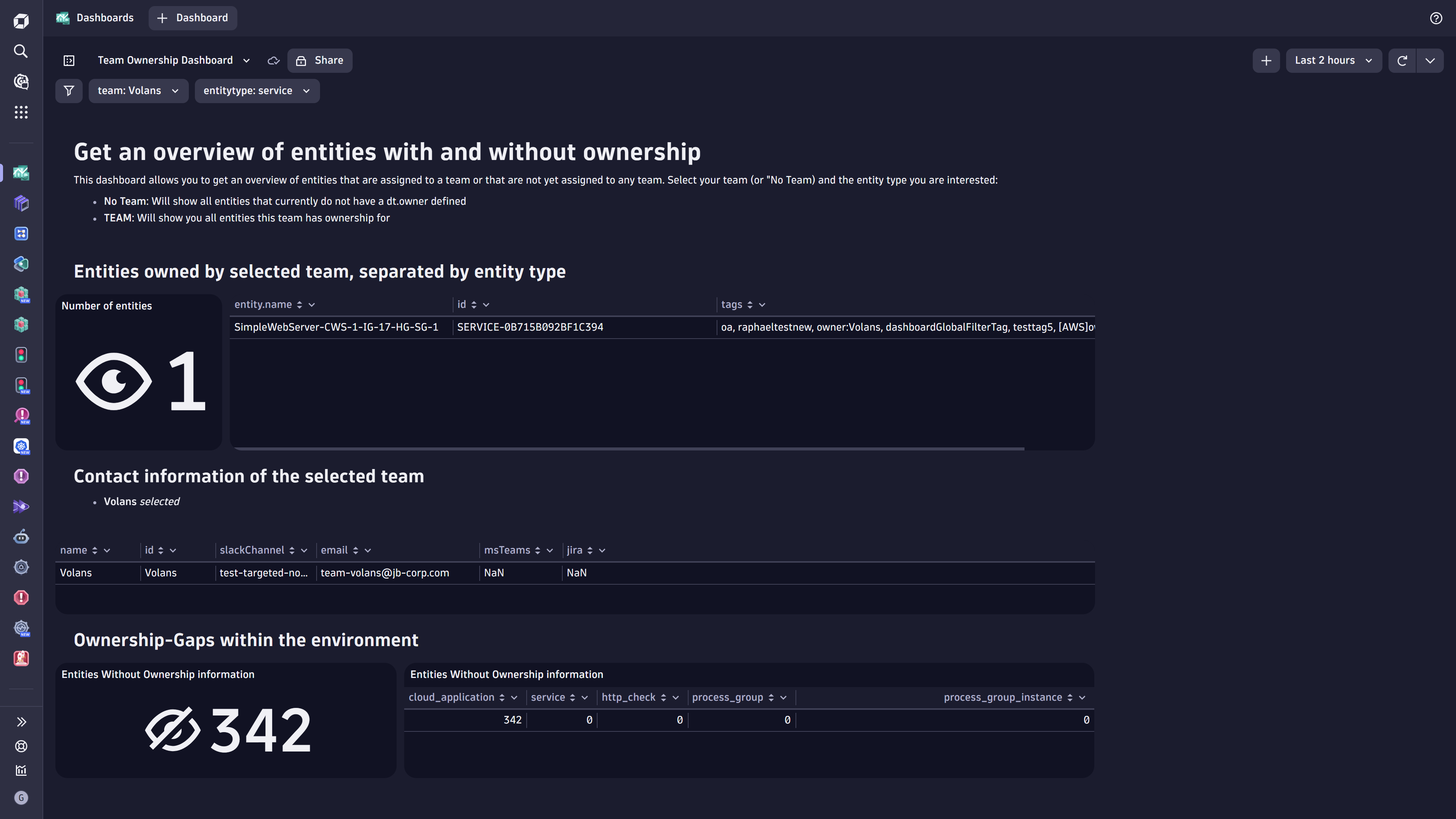 Figure 4. Dynatrace dashboard presenting an overview of ownership-team coverage within the environment
Figure 4. Dynatrace dashboard presenting an overview of ownership-team coverage within the environmentOwnership
If it comes to the worst case, and a security vulnerability is introduced or a severe incident happens, it’s important to automatically inform the responsible teams and start remediation actions.
With Dynatrace Workflows, triaging time can be minimized and eliminated. Based on the detected issue or event, a workflow can automatically retrieve the associated ownership teams during the execution. The dedicated get_owner workflow action, queries all teams of affected entities. Further the ingested ownership metadata, such as contact details can be used to prepare Jira tickets or notify the right teams with all the crucial information they need to immediately start issue resolution.
Some examples of how ownership information enables automated notification and remediation workflows are listed below.
- Automated Release Validation and notification of the responsible teams using the Site Reliability Guardian
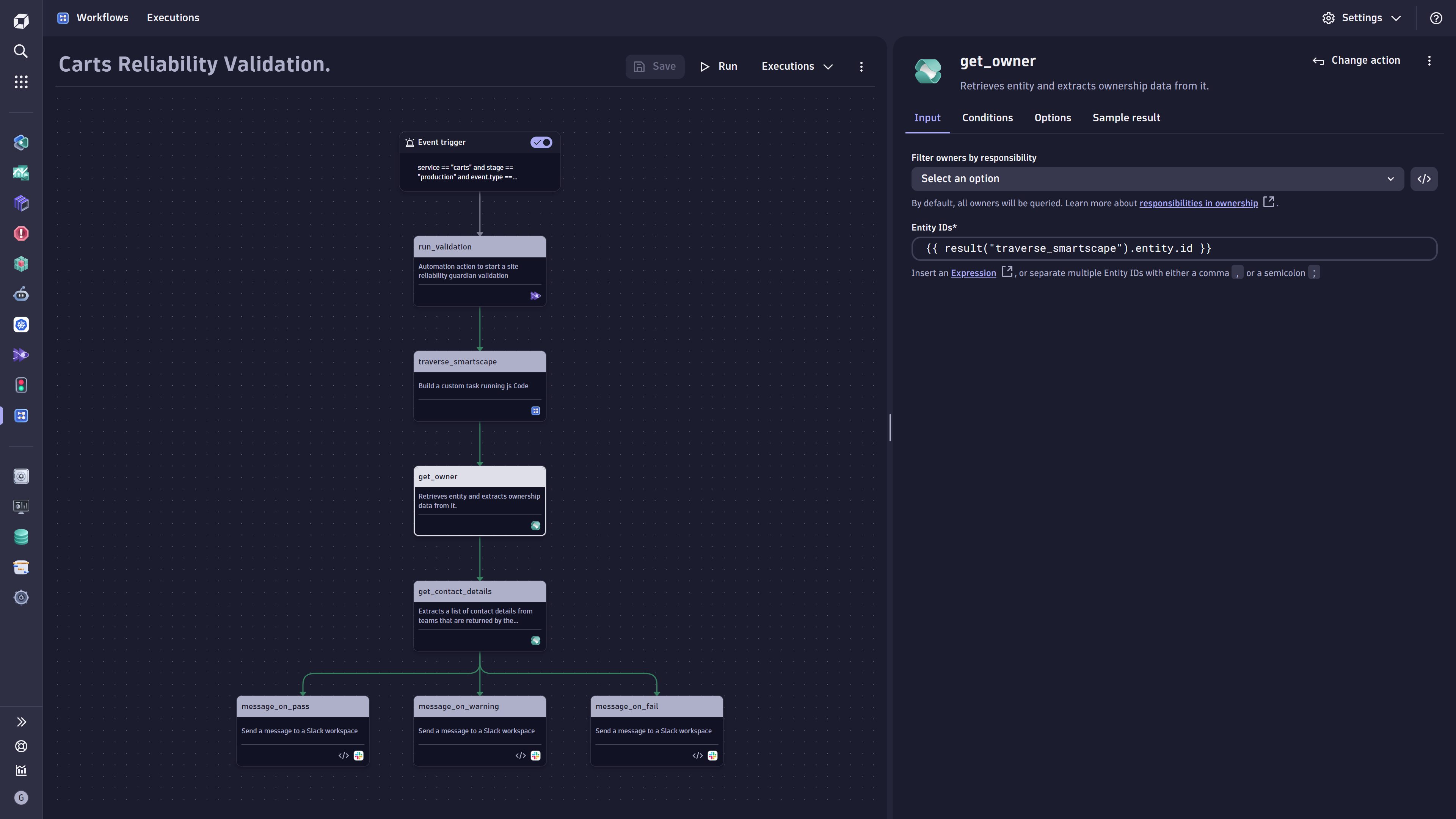 Figure 5. Sample workflow for an automated release validation
Figure 5. Sample workflow for an automated release validation- Problem Remediation Automation utilizing Red Hat Ansible Automation Platform
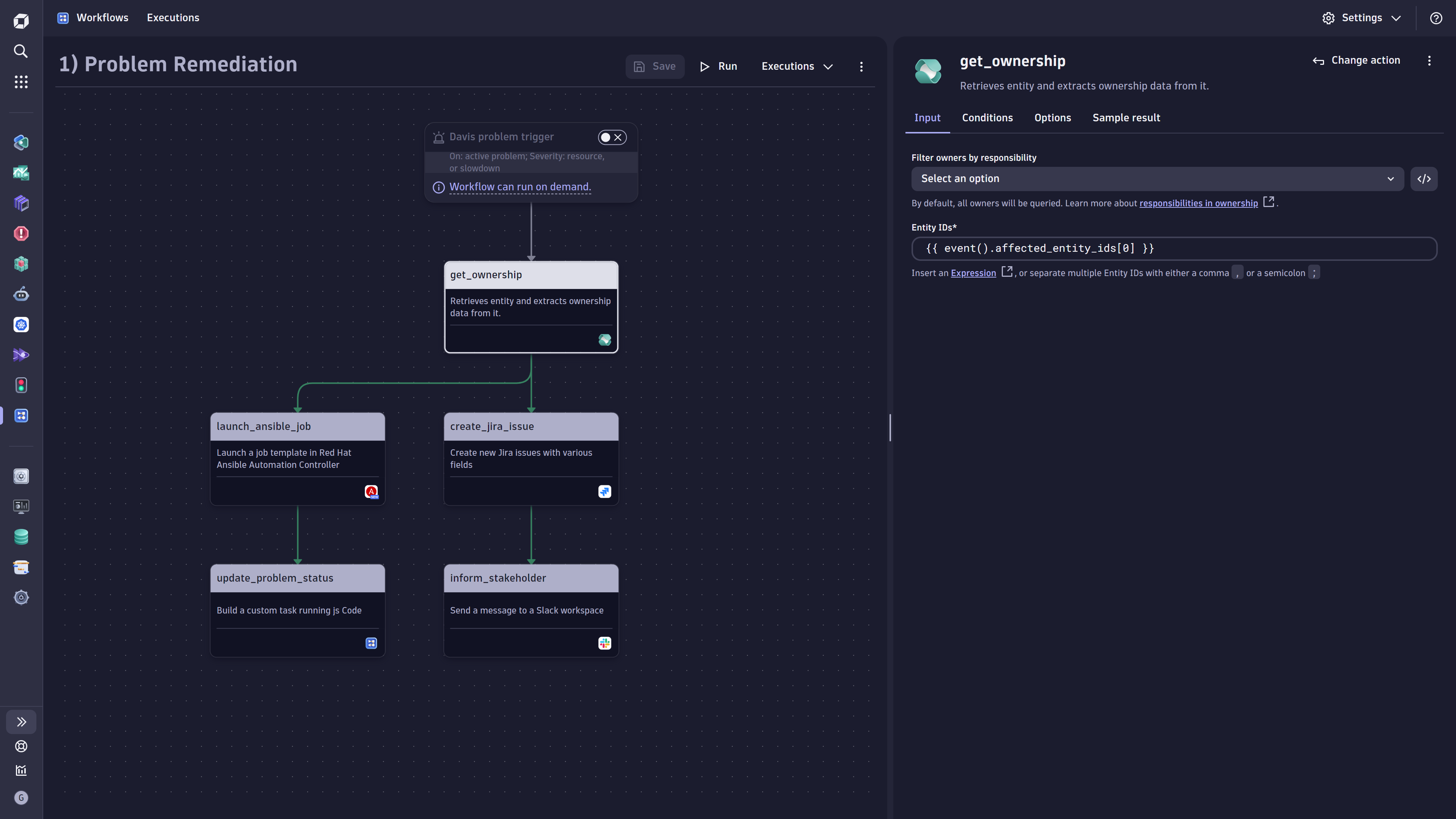 Figure 6. Sample illustrating problem remediation with a Red Hat Ansible Automation Platform integration
Figure 6. Sample illustrating problem remediation with a Red Hat Ansible Automation Platform integration- Kubernetes Workload Optimization
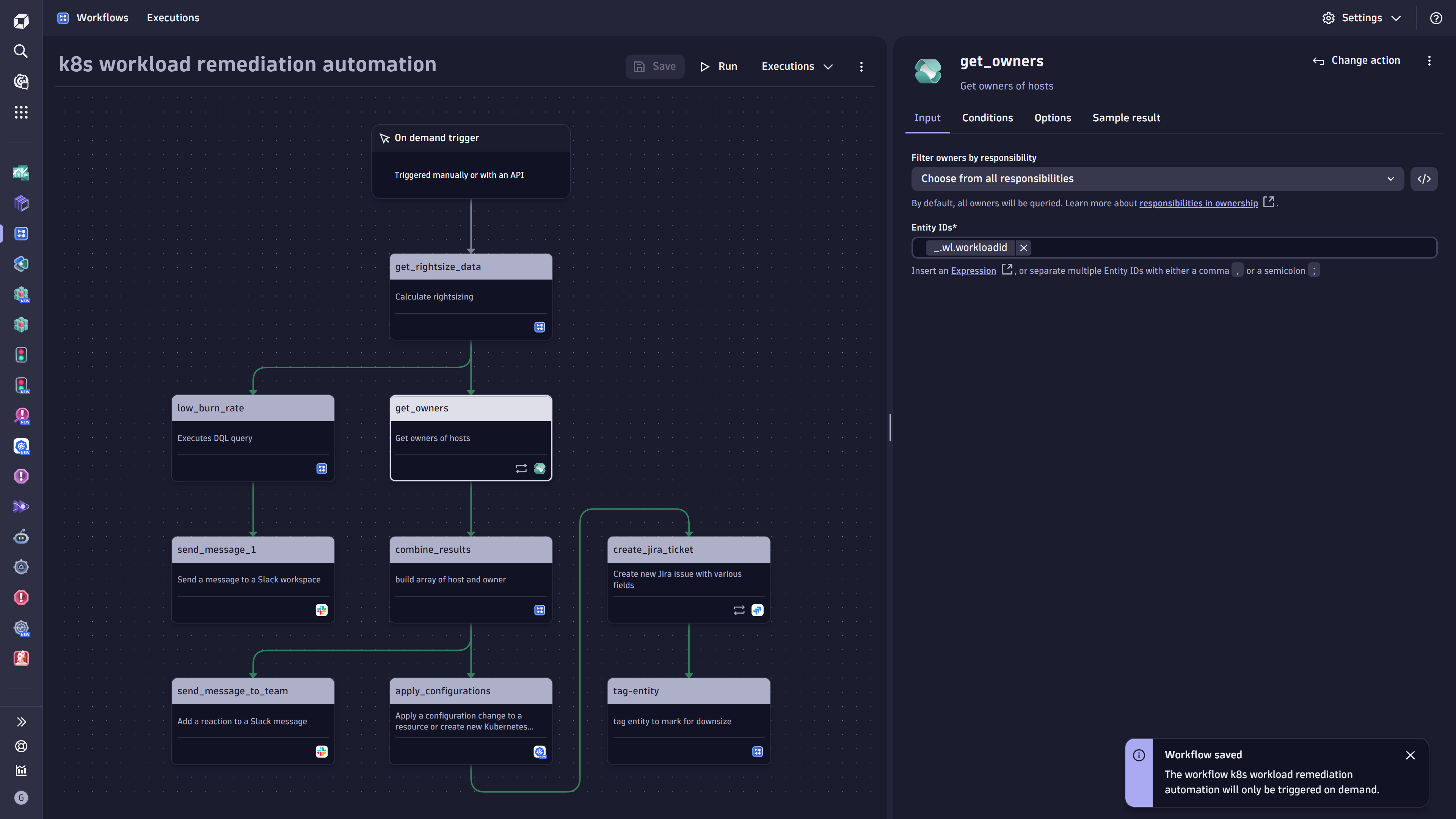 Figure 7. Sample workflow to automate Kubernetes workload optimization
Figure 7. Sample workflow to automate Kubernetes workload optimization- Security Vulnerability Processing
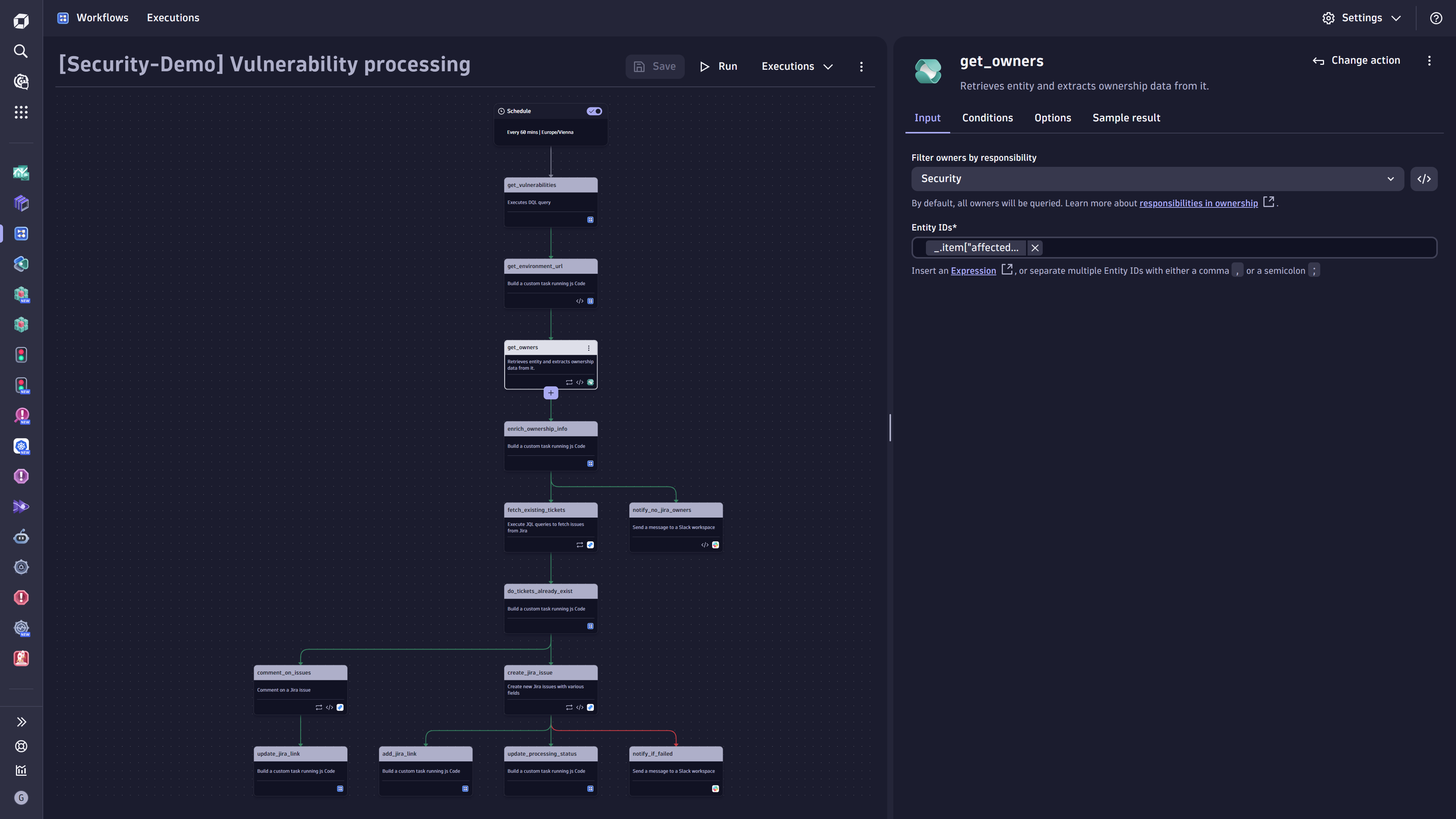 Figure 8. Sample workflow of a security vulnerability processing automation
Figure 8. Sample workflow of a security vulnerability processing automationAnother example of utilizing targeted notifications via Dynatrace Workflows can be found in this public GitHub repository. These examples can be extended to cover similar use cases as above.
What’s next
Dynatrace already provides the possibility to reference ownership team information from entities, ingest crucial ownership team metadata such as contact information in an efficient way, and offers automated access to this information either via the user interface or Dynatrace Workflows. This enables a wide possibility of use cases where automated and targeted notifications play a significant role in reducing MTTR and increasing efficiency and reliability.
To further improve the user handling of the ownership functionality, we are currently working on making this information easily accessible via DQL (Dynatrace Query Language). Making use of all relations and dependencies will further simplify the retrieval of necessary information reliably when needed.
Follow these steps to increase an environment’s transparency and prepare environments to automatically inform and notify the right people at the right time:
- Ingest ownership metadata, such as contact details, into a Dynatrace environment.
- Using the teams-importer to keep ownership data automatically in sync.
- An example of how to set up an ownership import workflow is given in our workflow-samples repository.
- Extend components and services with ownership information.
- Use object-specific and reliable association methods such as Kubernetes annotations, environment variables, host metadata, etc. More details can be found in Dynatrace Documentation.
- Detect blind spots and ownership gaps in environments.
- Use dashboards and notebooks to keep an overview of the current state and proactively detect blind spots.
- An example can be seen in our platform engineering demo (If you want to try out the platform engineering demo, please look at this repository, where you can run the demo within GitHub codespaces.
- Set up automation workflows, tailoring and targeting ticketing and remediation activities based on the affected entities and occurring events, problems, or security vulnerabilities. Checkout the already available examples within our publicly available Configuration as Code GitHub repository or our Dynatrace Discover tenant.
- Use dashboards and notebooks to keep an overview of the current state and proactively detect blind spots.
Contact us to schedule a demo. We’ll walk you through the various workflows and dashboards discussed in this blog post.
The post The right person at the right time makes all the difference: Best practices for ownership information appeared first on Dynatrace news.