 10 months ago
44
10 months ago
44
Introduction
The cloud, with its large numbers of the latest processors and scalable storage systems, is becoming indispensable to modern biomedical research organizations, who use it to generate and analyze vast amounts of data. However, research by its very nature is not a linear process, and so cloud resources must be flexible enough to rapidly scale up and down in response to changing demands. Additionally, research always has limited funding, and so cost- and time-efficiency are critical to achieving research insights.
Last year, the Salk Institute, a leading private, non-profit research institution, dropped computing costs by 20% and achieved stability and scalability with its pilot program with Google Cloud, a program which, for the first time, mapped the entire mouse brain at the molecular level.
Our journey began by leveraging Google Cloud services such as Spot VMs for dynamic low cost compute, Cloud Storage for bulk data analysis and archive, and Filestore for low latency data analysis. However, researchers needed a way to simplify the entire workflow, and be able to leverage cloud services in a straightforward way in any cloud region. While a variety of open and non-open-source tools exist, building an end-to-end solution is complex and requires stitching multiple tools together. Working together with the Google Cloud team, we learned about an emerging open-source project from UC Berkeley called SkyPilot, which simplifies the cloud workflow, reduces costs, and has become the backbone of our single-cell whole mouse brain analysis.

3D structure of key mouse brain regions that are the focal points of large computational analysis, encompassing tasks such as mapping cell sequencing data and conducting downstream analysis
“The elasticity provided by [Google Cloud] has enabled us to process and analyze complex biological data at an unprecedented scale,” said Professor Joe Ecker, director of the Genomic Analysis Laboratory at Salk. “The simplicity and effectiveness of SkyPilot further enhance our efficiency and reduce the cost for all our computational tasks. This has been instrumental in advancing our understanding of complex biological systems and accelerating our research outcomes.”
Mammalian brain in the cloud
The brain is one of the most intricate structures known to humanity, with billions of cells connected by trillions of synapses. Our laboratory aims to understand the molecular diversity of brain cells at cellular resolution for both mouse and human brains. This involves bioinformatics tasks that require substantial computational resources.
The process starts with collecting data from millions of cells in a wet lab. To analyze the cells in Google Cloud, the terabyte-scale data is uploaded to Cloud Storage, which provides a massive low-cost and highly resilient storage system that requires no maintenance.
To analyze the data, the primary workloads are divided into two phases:
- Batch jobs that map and preprocess the raw cell data into an analysis-friendly format
- Interactive development with JupyterLab to further analyze and visualize the cells
Batch jobs must run on more than one machine in order to complete in a reasonable amount of time. To understand why many jobs need to run in parallel across many machines, let’s look at genome mapping. Our current mapping pipeline takes approximately 1 vCPU hour for each cell. Given that the whole mouse brain dataset has approximately 0.5 million cells, it would take 217 days on a high-end 96-vCPU AMD machine (n2d-standard-96) to finish just one round of mapping. Google Cloud’s elasticity scales out the computation with virtually unlimited CPU resources, speeding up the process. In practice, computation time is reduced 32x by using 32 96-vCPU nodes and evenly distributing cell processing across them in an embarrassingly parallel way. Due to the relatively short time it takes to analyze each cell, Spot VMs are ideal to further reduce processing costs.
After the data is mapped and preprocessed, our scientists do interactive development to further visualize and analyze the data. Using a predefined Cloud image, each researcher launches their own JupyterLab VM on-demand. The VMs are configured to automatically set up and configure the environment, mount the Cloud Storage bucket with the processed cell data using GCSFuse, and start the JupyterLab software. With GCSFuse, the code running in the Jupyter Notebook can directly operate on the data on the Cloud Storage bucket as if it were a local file system. When lower latency I/O and better consistency between researchers is required, we also leverage Filestore to store the lightweight code and notebooks.
Sky Computing simplifies brain research in the cloud
While Google Cloud offers powerful capabilities, bioinformaticians want to interact with the cloud in as simple a way as possible, leveraging the cloud’s capabilities without becoming cloud experts, so they can spend more time on scientific research.
The goal of Berkeley’s Sky Computing project is to abstract away the gory details of how to run workloads in the cloud, allowing us to focus on the workloads themselves (hint: scientific discovery). Leveraging the open-source Sky Computing project SkyPilot simplified the entire end-to-end deployment of our AI and data science brain-analysis workflow. Sky Computing aligns well with Google Cloud’s mission of being an open cloud and strong supporter of open-source technologies, which gives us confidence that its use cases would be supported by this emerging ecosystem.
The first benefit of SkyPilot is that it automates most of the low-level provisioning, scheduling, and administration complexities. Tasks such as reliable provisioning of compute resources (with automated retries in case of failure or shutdown), VM configuration, repeatable deployments across zones and regions, and even reliable job scheduling are all automatically handled by the Sky Computing framework. These core capabilities are exposed in an easy-to-use YAML/CLI interface, increasing productivity.
The second benefit is that SkyPilot delivers the ability to deploy fully reproducible data analysis environments on Google Cloud. For both batch pipelines and notebooks, we specify four properties of the workload in a SkyPilot YAML file:
- Resources - Computational resources required (e.g., hardware, region)
- Data - Google Cloud Storage buckets containing the cell data. SkyPilot automatically mounts these buckets to all deployed compute instances using GCSFuse.
- Setup - Configuration commands for installing require software, e.g., bioinformatic packages
- Run - Commands to launch the workload. For our needs, this typically includes either launching a JupyterLab instance or running Snakemake, a popular bioinformatic pipeline package for batch pipelines.
An example YAML file showing these four parts is visualized below:
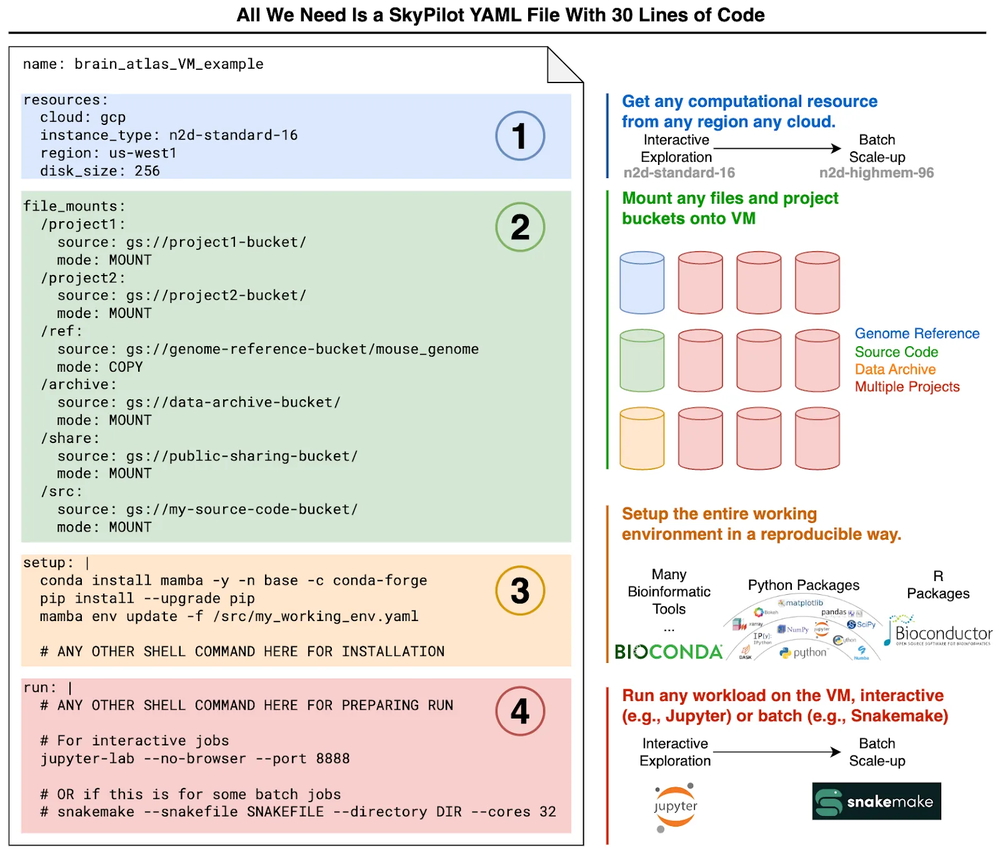
With a simple YAML template, we can launch a fully reproducible data science environment. The single YAML file encodes resources, data setup, environment setup, and workload commands to run. This generates a consistent environment for both notebooks or batch jobs.
The single YAML file encodes how to launch notebook or batch jobs. Now we have a “job-and-environment-as-code” specification that is easily repeatable.
The third benefit is being able to grow and shrink the number of compute instances in each job simply by changing a few YAML flags. Compute Engine’s flexible compute types and elasticity prove instrumental here. To scale up a single machine, we can switch from a small VM (e.g., n2d-standard-16) to a larger VM (e.g., n2d-highmem-96) with only one flag change. For scaling out our batch mapping pipelines, SkyPilot can easily run thousands of Snakemake jobs on Compute Engine.
Finally, Sky provides a more managed experience when using Compute Engine Spot instances to reduce the cost of its jobs. Spot VMs are a critical tool for large embarrassingly parallel jobs, as they are 60% to 91% cheaper than regular instances. Further, pricing is predictable as Google only changes the price at most once per month. For the beefy VM instances in Salk’s jobs, Spot pricing is about 6x cheaper than on-demand pricing (a cost saving that is too great to ignore!). However, naively using Spot instances means handling preemptions and/or out-of-capacity errors ourselves, which can be cumbersome.
Fortunately, SkyPilot greatly simplifies the use of Spot VMs for lowering compute costs. With one command, SkyPilot manages spot jobs by automatically restarting jobs when they are preempted, without user intervention. A lightweight controller VM launches one or more spot clusters to run the actual jobs. The controller monitors preemptions and re-launches the VMs as needed. The jobs periodically write checkpoints to Cloud Storage, which re-launched VMs can read to resume where the preempted VM ended. To overcome the periodic unavailability of enough Spot VMs in one region, SkyPilot is configured to recover spot clusters in any one of several regions. All of this has provided us with basically an unlimited amount of low-cost compute.
This SkyPilot Spot Management architecture is shown below:
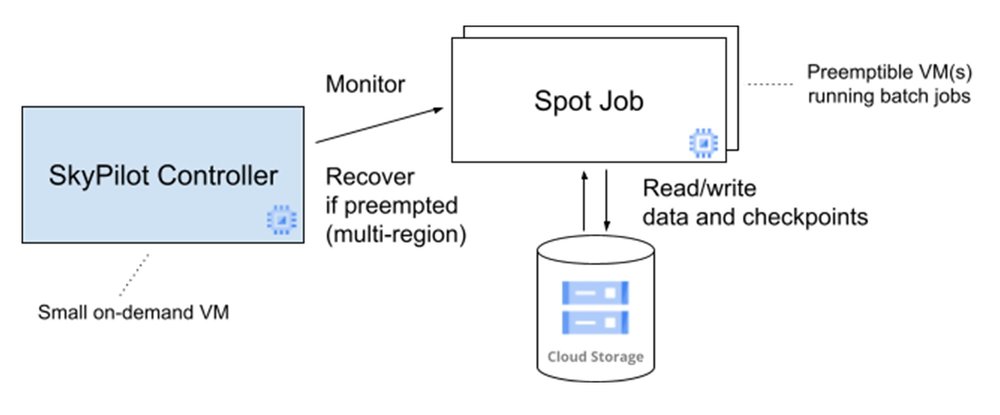
With SkyPilot’s managed spot functionality, we consistently achieve ~5.7x cost savings (Spot VM savings minus controller costs). The cost-efficiency enables significantly more computations on Google Cloud.
In short, combining the open-source Sky Computing technology with Google Cloud makes it much easier to leverage cloud capabilities. This combination has enabled us to complete multiple large-scale studies on Google Cloud with high productivity and cost-efficiency.
“At Berkeley we are building SkyPilot to enable users to run more jobs on the cloud with lower effort and higher efficiency. In 2023, SkyPilot launched more than 125,000 VMs into public clouds. It’s great to see Google Cloud participating in the Sky Computing ecosystem thanks to Google’s Open Cloud approach. This integration has enabled Salk’s scientists to focus on bioinformatics and run more computations in a shorter time.” - Zongheng Yang, Postdoctoral Researcher, Sky Computing Lab, UC Berkeley
For a detailed description of Salk Institute’s Ecker Lab’s use of SkyPilot on Google Cloud, please see the following article.
The future of brain research in the cloud
Over the next five years, the Human Brain Project will accumulate an ever-increasing volume of data, and will be confronted with the pressing issue of managing ever growing amounts of data. The data generation rate is substantial, comprising 36K single-cell methylome and 300K single-cell spatial transcriptome data every week, resulting in a staggering 50 TB per week (along with 108K vCPU-hours to process those cells). Managing the data growth in a simple and cost effective manner without sacrificing the ability for researchers to easily access, operate and manage the data continues to be a grand challenge. For some of the data transfer components, another Sky Computing project, Skyplane, promises to simplify and accelerate data transfers between on-premises to Cloud Storage.
And as compute and storage needs grow, we will need to deepen our investigation into how SkyPilot can help to distribute jobs across more zones and regions to ensure continued access to Spot VMs. The increase in the number of regions will raise new data management challenges as we strive to co-locate compute and data, while minimizing egress costs.
Last but not least, we’ll need to find better ways of building hybrid solutions that allow us to seamlessly run and migrate jobs and data across on-premises and Google Cloud. Combining the local resources with the cloud enables a flexible offering that provides exactly the right resources at the right time. One promising path forward here is to leverage Kubernetes on-premises and Google Kubernetes Engine in Google Cloud, and using SkyPilot’s emerging Kubernetes feature to manage resources across both deployments. It promises to be an interesting journey!
Thanks to Hanqing Liu, Junior Fellow at Harvard University; Anna Bartlett and Wei Tian, Ecker Lab, Salk Institute; the entire UC Berkeley Sky Computing team; and Ben Choi, and Derek Oliver at Google for their invaluable contributions to this article.