 13 hours ago
6
13 hours ago
6
As generative AI moves from experimental pilots to massive production environments, the efficiency of your infrastructure becomes the ultimate differentiator. One way to get the most out of it and minimize costly accelerator idle time is to leverage the Google Kubernetes Engine (GKE) Inference Gateway, which intelligently routes generative AI workloads based on real-time model server metrics.
Instead of relying on traditional, naive round-robin load balancing — which frequently triggers expensive accelerator recomputation and spikes user latency — this native extension of the GKE Gateway utilizes advanced capabilities like prefix caching and model-aware routing. By ensuring requests land on the exact accelerator that is primed to process them right away, GKE transforms how you can serve your large language models (LLMs), with excellent hardware utilization and ultra-fast response times.
In fact, according to an independent benchmark report, GKE Inference Gateway outperforms the next leading managed Kubernetes service with 15.7% higher throughput, 92.8% shorter wait times, and 62.6% lower inter-token latency. This performance takes LLM-based applications from sluggish and expensive to fast and production-grade.
That performance tracks with Snap’s experience using GKE Inference Gateway.
“At Snap, we are integrating llm-d into our production AI infrastructure to facilitate high-performance inference at scale. By employing prefix-cache-aware routing, we have achieved prefix cache hit rates ranging up to 75-80%. We appreciate the open-source nature of llm-d, as it enables seamless integration with our Envoy-based Service Mesh.” - Vinay Kola, Senior Manager, Software Engineering, Snap Inc.
In this blog, we take a closer look at GKE Inference Gateway’s prefix caching, complete with examples. We also provide more details about its benchmark results. Let’s jump in.
The secret to low-latency AI: Prefix caching
Prefix caching optimizes LLM performance by storing the KV cache (activation states) of long, repetitive prompt prefixes. When consecutive user requests share the same system instructions, context, or documentation, the model entirely skips reprocessing those tokens. GKE Inference Gateway reads incoming request prefixes and matches them to the specific pods that already hold that data in memory. This eliminates the "thinking" tax on your GPUs and TPUs, turning heavy reasoning loops into near-instant answers.
Use case 1: Documentation and codebase Q&A with retrieval-augmented generation (RAG)
When querying massive enterprise repositories, you can ground your LLMs’ responses without any added latency by pinning entire documentation sets as static cached prefixes, using RAG.
Instead of forcing an LLM to re-read thousands of lines of API references or corporate wikis for every single user question, GKE Inference Gateway routes the query to a pod that already has that specific context warmed up in its KV cache. The LLM only has to compute the user's brief, dynamic question, completely bypassing expensive document re-evaluation.
Figure 1: Prompt breakdown for a software troubleshooting scenario showing cached static prefix and dynamic suffix that changes per request
Use case 2: Multi-turn chat
You can also use prefix caching to maintain customer service interactions across thousands of simultaneous sessions without compounding compute costs. You can do so by caching permanent system personas and core business rules directly on the LLM server.
In enterprise chat architectures, the base system prompt and reference tables remain completely identical across millions of customer interactions. GKE Inference Gateway handles these multi-turn conversations using context-aware routing to bypass repetitive token processing, so that your chatbot stays ultra-responsive even under peak traffic.
Figure 2: The above prompts illustrate the static prefix and the dynamic, per-request components of a banking chatbot interaction
GKE outperforms alternative managed Kubernetes solutions
To validate these architectural advantages, Principled Technologies recently released an independent benchmark report comparing GKE (equipped with the GKE Inference Gateway) against a standard third-party managed Kubernetes service utilizing conventional round-robin HTTP load balancing.
Tested on a Llama 3.1 8B Instruct shared prefix workload using identical hardware (eight NVIDIA A100 40GB GPUs) the results reveal a massive performance gap between the two Kubernetes services. GKE didn't just win; it completely redefined inference efficiency across three critical metrics:
-
Higher throughput: 15.7% more tokens processed per second, enabling higher request capacity or reduced hardware needs for the same workload
-
Much faster time to first token (TTFT): 92.8% shorter wait times, producing dramatically quicker perceived response starts for interactive scenarios
- Lower inter-token latency (ITL): 62.6% reduction, resulting in smoother and faster token streaming after the first token
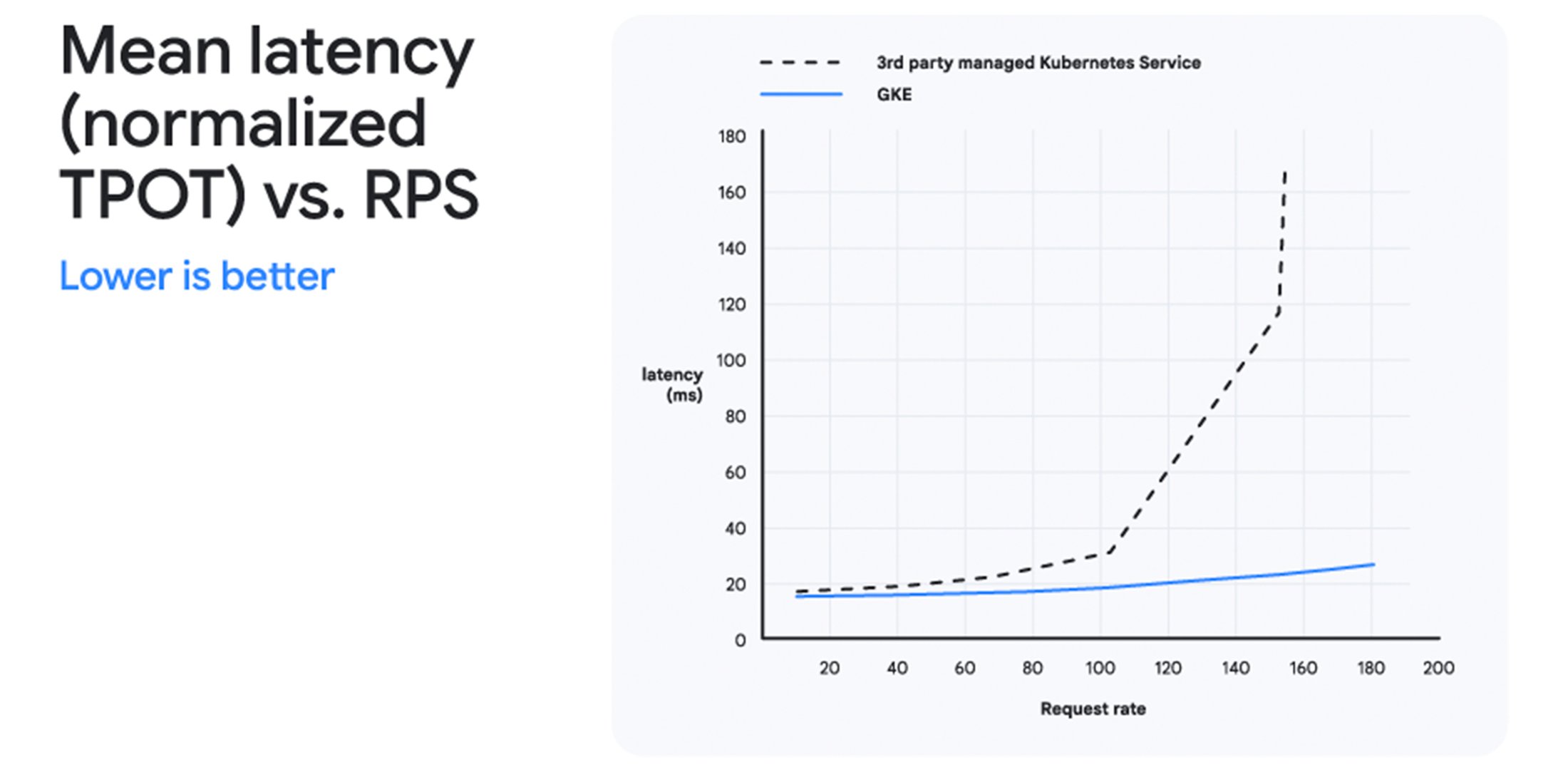
Figure 3: Mean latency (normalized time per output token) of GKE with GKE Inference Gateway and third-party managed Kubernetes service on the Llama 3.1-8B Instruct LLM on the Shared prefix use case. Both solutions used the same hardware. Source: Principled Technologies
|
GKE |
3rd party ManagedKubernetes Service |
GKE Advantage |
|
|
Mean outputtoken throughput |
7,169.21 outputtokens per second |
6,042.05 outputtokens per second |
15.7% more outputtoken throughput |
|
Mean time tofirst token (TTFT) |
188.36 ms |
2624.73 ms |
92.8% less TTFT |
|
Mean inter-tokenlatency (ITL) |
30.20 ms |
81.03 ms |
62.6% lower ITL |
Figure 4: GKE with GKE Inference Gateway delivered superior AI inference compared to a third-party managed Kubernetes service using standard HTTP LB.
Ready to accelerate your gen AI inference workloads?
Whether you’re deploying inference workloads such as real-time customer support agents, dynamic coding assistants, or sub-second fraud detection models, infrastructure latency dictates your user experience. By ensuring shared prompt prefixes hit the active cache nearly 100% of the time, GKE Inference Gateway transforms your LLMs from sluggish, expensive reasoning engines into rapid, capital-efficient, production-grade powerhouses.
Ready to explore the performance advantage that GKE Inference Gateway can bring to your gen AI workloads? Access the full benchmark report here and watch this explainer video to learn more.
A special thanks to Dan Sullivan, Senior Performance Architect, Principled Technologies.