 8 months ago
84
8 months ago
84
Digital transformation continues surging forward. Today, speed and DevOps automation are critical to innovating faster, and platform engineering has emerged as an answer to some of the most significant challenges DevOps teams are facing.
With higher demand for innovation, IT teams are working diligently to release high-quality software faster. But this task has become challenging. Data proliferation and the increased complexity of modern multicloud environments are nearly impossible to manage without automation. And according to the 2023 DevOps Automation Pulse, many organizations still have a long way to go: 72% reported that they do not have a clear DevOps automation strategy. Finally, this complexity puts additional burden on developers who must focus on not only building more complex applications, but also managing the underlying infrastructure.
Platform engineering: App delivery and operations as a product
Platform engineering — an internal self-service offering that automatically creates application infrastructure and tooling — holds promise as a method to overcoming DevOps inefficiencies. “The software delivery pipeline is becoming as business critical as any other product or service,” said Dynatrace founder and CTO Bernd Greifeneder at the 2023 Dynatrace Innovate conference in Barcelona. “It needs to be engineered properly as a product or service, and it needs automation, observability, and security in itself.”
Dynatrace chief technology strategist Alois Reitbauer joined Greifeneder at Innovate to discuss key DevOps automation and platform engineering use cases. During the session, Reitbauer dove into several business-critical, high-impact examples of how customers can wield platform engineering in the Dynatrace platform out of the box and throughout the entire software delivery lifecycle.
Everything as code: GitOps as the standard
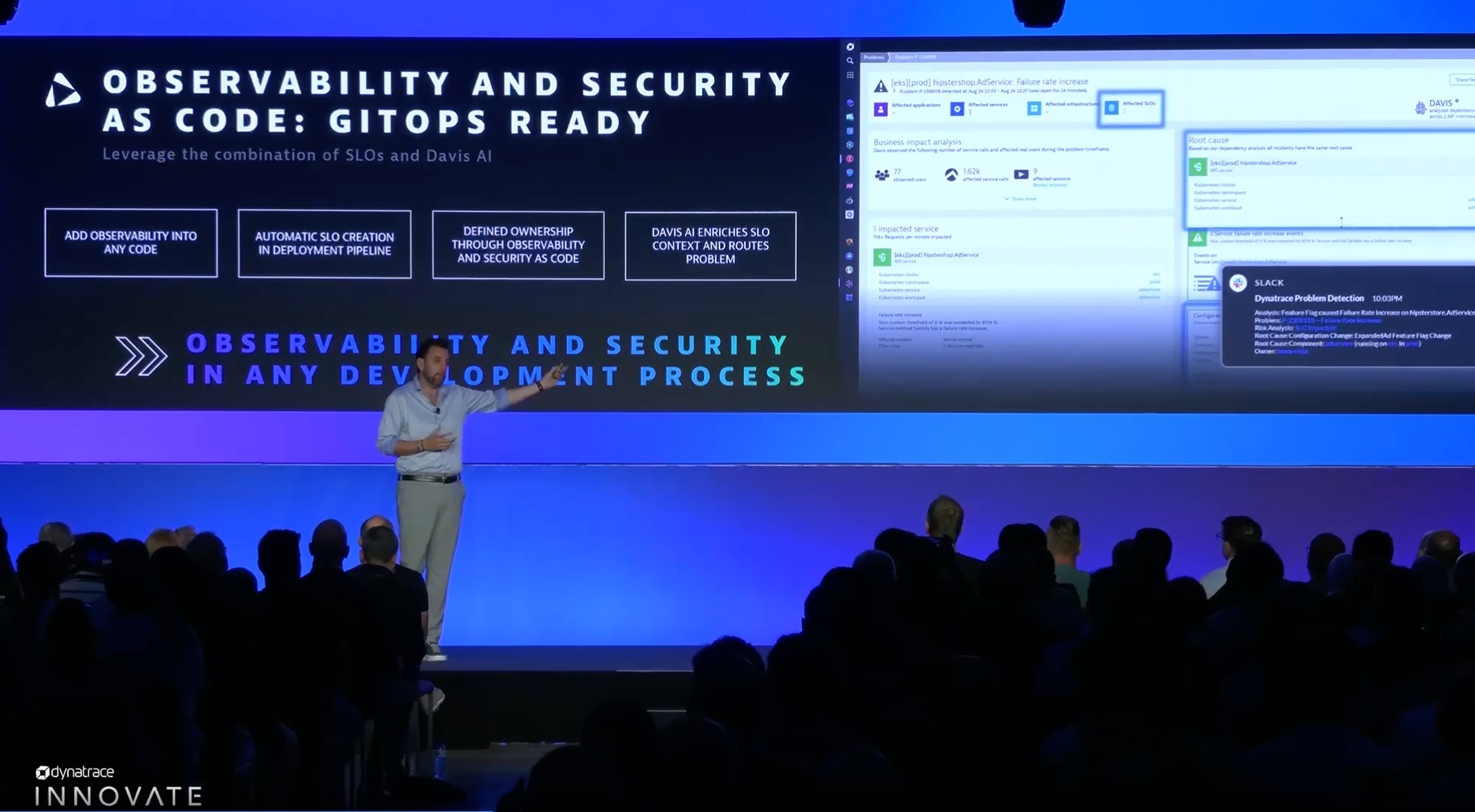
Observability as code is used to programmatically define observability and security. When Davis identifies a problem, the additional context enriches the alert with information to identify the release, deployment, ownership, and even remediation actions. This context arrives automatically.
Unified observability and security in the development process are crucial to defining ownership in the development process. From performance issues to vulnerabilities, problems can crop up anywhere in the software development pipeline. Incorporating unified observability and security as code defines ownership, automatically creates service-level objectives (SLOs), and routes problems for speedy mean time to repair.
“Everything is ‘as code’ in Dynatrace,” said Reitbauer. “Every developer is empowered to enter observability information along their code so that monitoring and managing are no longer separate from building code.”
Release validation for observability and security

Releasing secure, high-quality software is critical with today’s demand for rapid innovation. The data provided by Dynatrace Grail helps teams understand software quality and whether now is a good time to release.
Using quality and security gates ensures releases meet SLO criteria, ultimately reducing production deployment lead time. Quality and security gates help with understanding not only software quality but also security. Teams can use gates to ensure that no vulnerabilities are entering into the production pipeline.
Dynatrace AutomationEngine fully automates this entire process. AutomationEngine links these processes to your team’s progressive delivery pipelines. Every push automatically runs through quality and security gates, resulting in high-quality, secure, and reliable releases.
FinOps as an integral building part

As organizations move to the cloud and their environments become increasingly complex, cloud cost management becomes essential. One of the keys to managing cloud costs is ensuring that operations are running efficiently.
Often, organizations choose to reduce costs by running their infrastructure on reserved instances. Dynatrace helps organizations optimize their cloud spend by enabling teams to import real-time cloud cost data into Grail. Notebooks analyze the data and identify anomalies, spikes, and resource gaps to illuminate where teams can optimize with reserved instances. These capabilities run automatically and can standardize cloud cost reporting to a daily basis rather than monthly.
“We’re even pushing this forward,” said Reitbauer. “The next step of this deployment will be that every developer team will see how much their software consumes in production. We’re bringing cost awareness to the development teams.”
From reactive to predictive operations

The key to software running perfectly is anticipating operational issues before they emerge. The Kubernetes clusters that the Dynatrace platform is running are large; the number of clusters running will continue to increase with more innovation. But it is not only the number of clusters that matters, but also the storage underneath. As of today, the platform runs roughly 17,000 Kubernetes pods that need storage underneath. Optimizing the storage of each individual node would be nearly impossible for a human being to manage.
We use the Davis predictive AI capabilities to predict when disk space will likely run out. As Davis detects that a node might run out of disk space, it predicts and provisions the correct amount of additional disk space so that everything runs without interruption. Teams know not only that they must scale but also by how much. Moreover, clusters can scale proactively with predictive capabilities, reducing the likelihood of performance issues and degradations.
Runtime security with ownership information for real-time vulnerability resolution
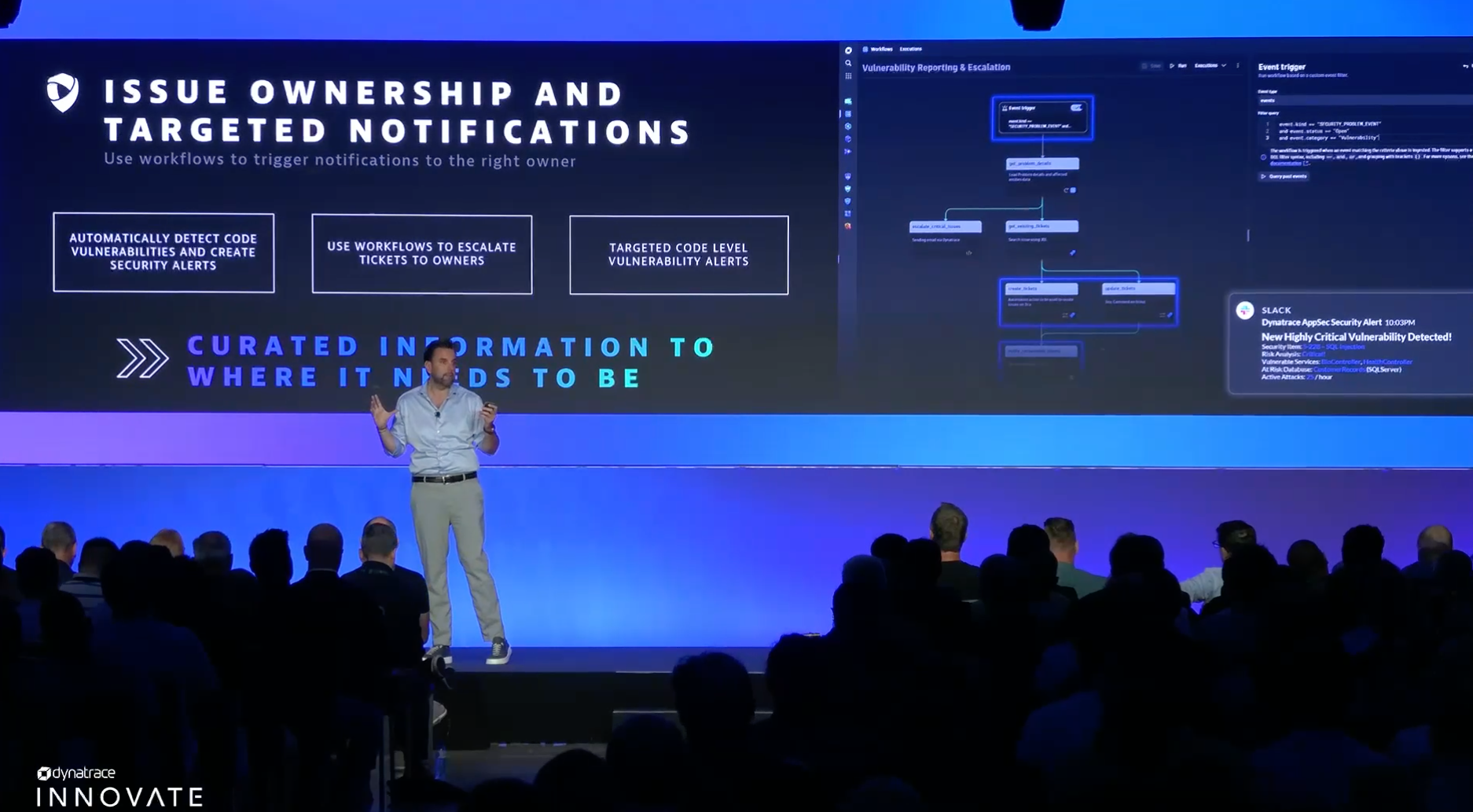
In addition to software reliability and performance, security is a great concern among organizations. In wake of large incidents such as Log4Shell, organizations are investing in security measures to prevent cyberattacks and vulnerabilities. But one of the toughest challenges to navigate is routing: in the event of a security incident, getting the necessary information to the right person is highly time sensitive.
Teams can use Dynatrace workflows to ensure that issue notifications get to the right person at the right time before problems escalate. Automatic vulnerability detection identifies code-level issues and creates precise alerts with context. Dynatrace workflows use ownership information to escalate security tickets to the right owner for speedy resolution.
“The biggest challenge with a security issue is ensuring the right person sees it at the right point in time,” said Reitbauer. “By taking human analysis out of the equation, a process that might take hours or even days can become one that takes minutes or less.”
Improving customers’ experience with Session Replay and real user monitoring

Finally, as customer-facing organizations scale and earn more users to their applications, the volume of support tickets typically increases.
Dynatrace real user monitoring (RUM) and Session Replay handle the volume of tickets to pinpoint the root cause of issues quicker than a traditional, manual approach. RUM and Session Replay enable digital experience teams to gain a more granular understanding of the customer journey and context of how backend performance issues are affecting end users. With faster access to information, the resolution process begins sooner. Customer satisfaction increases as problems are resolved swiftly and with minimal interruption.
We don’t stop here: empowering platform engineering at scale

With more than one hundred platform engineering use cases across over twenty categories, Dynatrace’s out-of-the-box capabilities empower organizations to use platform engineering and DevOps automation to fit their specific needs.
Don’t see the critical use case you’re looking for? AutomationEngine and AppEngine help organizations create custom use cases on top of the Dynatrace platform. AutomationEngine and AppEngine leverage the same data that Dynatrace and Grail use so that the possibilities are endless.