This blog was authored by Johannes Brück, Senior Staff Engineer (Personio), Donald Dragoti, Lead Platform Engineer (Personio), Steve Flinchbaugh, Lead Platform Engineer (Personio), Maximilian Schellhorn, Senior Solutions Architect (AWS) and Dionysios Kakaletris, Technical Account Manager (AWS).
Migrating your Amazon Elastic Kubernetes Service (Amazon EKS) nodes to use AWS Graviton based Amazon Elastic Compute Cloud (Amazon EC2) instances can lead up to 40% better price performance and use up to 60% less energy than comparable EC2 instances for the same performance. However, the application rollout on multiple CPU architectures necessitates preparation and adaption to your operational requirements.
In this post, you get an overview of strategies and best practices for migrating your application to AWS Graviton. First, we demonstrate how to build multi-architecture images within a dedicated build pipeline and the considerations for local emulation. Then, you learn why a gradual rollout process is important and how to effectively implement it using Karpenter on Amazon EKS. Finally, you get insights into monitoring your applications during the migration, and which tools are available to visualize the long-term success of your migration. The following figure outlines the high-level architecture.
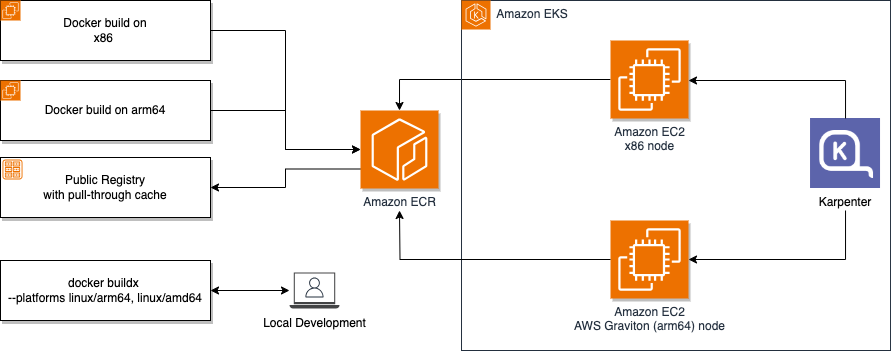
Figure 1: High level architecture
Using multi-architecture container images
When preparing to gradually move your containerized workloads to AWS Graviton, you need to ensure that the container images are available for both processor architectures. This includes not only your application and services, but also any sidecars (such as service mesh proxies) or DaemonSets (such as observability agents) and any other third-party software needed to run on your nodes.
To understand the difference between a single-architecture and a multi-architecture image, you can use the Docker command line interface (CLI) to inspect the container image. A single-architecture image has a mediaType of image manifest and references the various layers of the container image. A multi-architecture image has a mediaType of image index and references multiple image manifests with their respective platform:
For images where arm64 support is missing, it is generally advisable to search for existing public resources, such as open issues and pull requests on the source repository (if applicable). This can help you understand if others have already reported the issue and whether any progress is being made. Furthermore, you can collaborate with the community on the development of arm64 support for the upstream image.
As an alternative you might have to build and maintain the image and push it to a private registry, such as Amazon Elastic Container Registry (Amazon ECR). The commands to achieve this vary depending on the software. Although you can’t build an arm64 compatible version on top of the original container image, you can analyze the inner workings to start building your own custom image.
For example, imagine the original image is retrieving an architecture specific binary release from GitHub. If the binary is available for multiple architectures, then you can use the $TARGETARCH variable in the Dockerfile. This variable is provided by Docker (among others) during the build process, and resolved to the target platform for which you are building:
Building multi-architecture container images
After creating the arm64 compatible Dockerfile you can start to build your image. It is recommended to use dedicated build machines for your target architecture to accelerate build processes and avoid emulation. These machines are usually created within a fully automated continuous integration and continuous delivery (CI/CD) pipeline. If you want to learn more, refer to this AWS DevOps post. Then, the build commands are executed on the respective machines:
After these images have been built and pushed to the registry, you can create the manifest list and annotate it with both architectures referencing the pushed images. Finally, the manifest is pushed under a custom tag:
For local development or proof of concepts (PoCs) where a longer build duration is acceptable, you can use docker buildx. This Docker plugin runs different builds for a list of specified target platforms and creates a manifest list.
The following example triggers the build for two platforms with an automatic push to an Amazon ECR repository:
This approach means that both container image builds can be executed on the same host. If the build is running on an x86 machine, then buildx emulates the arm64 machine and the other way around. This might impact the performance of the build and varies significantly depending on the type of task and programming language used. For example, although copying a file into the image is fast, installing a PHP PECL extension that might need to be compiled from sources would result in longer build times because of emulation. Therefore, we don’t recommend using this approach for production workloads.
Even when built-in support for cross-compilation is given and the performance impact of emulation is reduced (such as Go), further caution is needed. Docker also uses the –platform setting to determine the architecture of the base image that you specified in the FROM statement. Therefore, a build on x86 would still lead to emulation because the build itself pulls an arm64 image. To avoid this, you can set the platform explicitly on the source image using the $BUILDPLATFORM variable. This forces docker to select the architecture according to the current instance architecture.
After successfully identifying, building, and pushing multi-architecture images you are ready to start using them. In general, you can continue to use your upstream or public images that are directly referenced in your Kubernetes manifests. However, using a private Amazon ECR image registry to mirror public registries allows you to decouple your system from the availability of third-party services and use high download rates for your container artifacts.
To achieve this, you can either 1/ create a job that is periodically pulling container images from a public registry and store them in Amazon ECR, or 2/ use the Amazon ECR pull-through cache.
For 1/ you need to ensure that the image’s architecture pushed to Amazon ECR is decoupled from the processor architecture on which the job is executed. For example, if you’re running docker pull repository_name/image_name:tag and then push to Amazon ECR on an x86 EC2 instance, you create an x86 image in Amazon ECR. To address this, you can use the –platform option or simplify this process by using tools such as skopeo or crane.
Option 2/ allows you to be fully dynamic and support newer images and image tags without having to add them to a mirroring job manually. To setup the pull-through cache feature you can use the AWS Command Line Interface (AWS CLI):
You can reference the new image URL in the Kubernetes Deployment spec:
After the Kubernetes manifests have been updated and the pods are able to use multi-architecture images, the next step is to prepare the AWS Graviton nodes to run the pods.
Scheduling AWS Graviton-based nodes with Karpenter
To schedule AWS Graviton-based nodes in the EKS cluster using Karpenter, you can either expand the existing NodePool to support multiple architectures or create separate NodePools for AWS Graviton and x86 nodes. The latter offers more control for you to independently configure the EC2 instance selection for the different architectures. Furthermore, you can use NodePool limits and priority weight to control the rollout of AWS Graviton-based nodes instead of leaving it up to Karpenter.
The following is an example AWS Graviton-based NodePool Karpenter configuration:
For the gradual rollout of the pods the example uses the taints and tolerations Kubernetes concepts. The graviton-migration taint marks the node to not accept any pods that don’t tolerate the taint. This mechanism allows you to have full control over which pods are scheduled on AWS Graviton-based nodes during the migration.
To tolerate the taint the Kubernetes pod specification of an application needs to be adapted:
Migrating your workloads
With the multi-architecture container image built and the Kubernetes tolerations applied, your services can now run on AWS Graviton nodes. However, the current set up means that the pods aren’t forced onto these nodes. Karpenter and the Kubernetes scheduler work together to determine if and when AWS Graviton-based nodes are provisioned. Karpenter (Version 1.0) uses the lowest-price allocation strategy for on-demand and price-capacity-optimized for Amazon EC2 Spot Instances. After Karpenter has provisioned the nodes, the Kubernetes scheduler schedules the pods onto the available capacity.
Enabling pod scheduling on both x86 and arm64 architectures provides scheduling flexibility and facilitates faster rollbacks if needed. You can swiftly revert back by removing the toleration if you encounter performance issues or increased error rates. To mitigate the risk of unexpected regressions or performance degradation and maintain stability, consider implementing the following gradual rollout strategy:
- Start with low-risk services to validate the setup. The AWS Graviton Transition Guide is a good starting point for identifying these workloads. For example, interpreted or JVM based applications might run as-is with only minor adjustments.
- Progress to larger services or low-level optimized compiled applications.
- Continue with mission-critical services requiring close collaboration between platform and product teams to ensure smooth service operation and quickly address any performance regressions.
When you are confident for the rollout, you can force services onto the AWS Graviton-based nodes with an addition to the pod spec:
A full pod spec for your service that runs exclusively on AWS Graviton-based nodes might look like the following:
Simplifying migration with Helm
To simplify the migration to AWS Graviton for product teams, you can use Helm to automatically apply the necessary configurations.
Helm allows you to wrap the Pod tolerations in an if clause:
This allows you to enable AWS Graviton support for your service using a configuration in values.yaml:
Monitoring rollout progress
As with any migration you can build confidence in your process by deploying to a non-production environment first, thereby providing a low-risk, quick feedback loop. For production environments, use strategies such as canary or blue-green deployments. These approaches allow you to monitor for increased error rates or performance regressions by tracking service latency. Robust deployment mechanisms mean that any issues in migrating to the new compute architecture can become immediately apparent, allowing for automatic rollbacks if necessary.
After deploying to production, use your observability tools to further validate performance. Key metrics to monitor include application latency, error rates, and resource consumption. A successful production deployment, coupled with stable metrics, significantly increases confidence in your migration.
To monitor the overall progress of your migration to AWS Graviton, use Karpenter metrics. For example, using karpenter_nodepools_usage to compare the share of AWS Graviton scheduled capacity to the total capacity, as shown in the following figure.
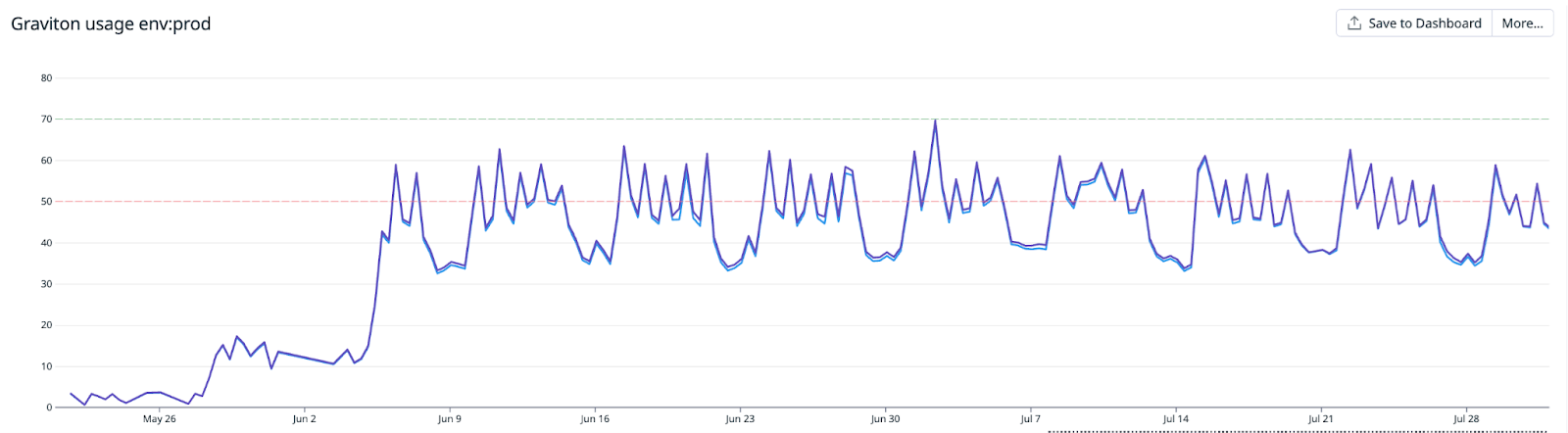
Figure 2: Monitoring AWS Graviton usage
By closely monitoring these metrics, you can make sure of a smooth transition to AWS Graviton-based nodes and maintain application performance and reliability.
After the services are migrated to AWS Graviton, remember to clean up the supporting infrastructure and configurations. This includes removing taints and tolerations and deleting the old NodePool so that Karpenter doesn’t schedule any new nodes with the x86 architecture.
Measuring success with Graviton Savings Dashboards
After completing your migration you might want to visualize and analyze the benefits of using AWS Graviton-based nodes across your organization. The Graviton Savings Dashboard helps you get an overview of the processor architecture usage and outlines the savings in comparison to other architectures, as shown in the following figure.
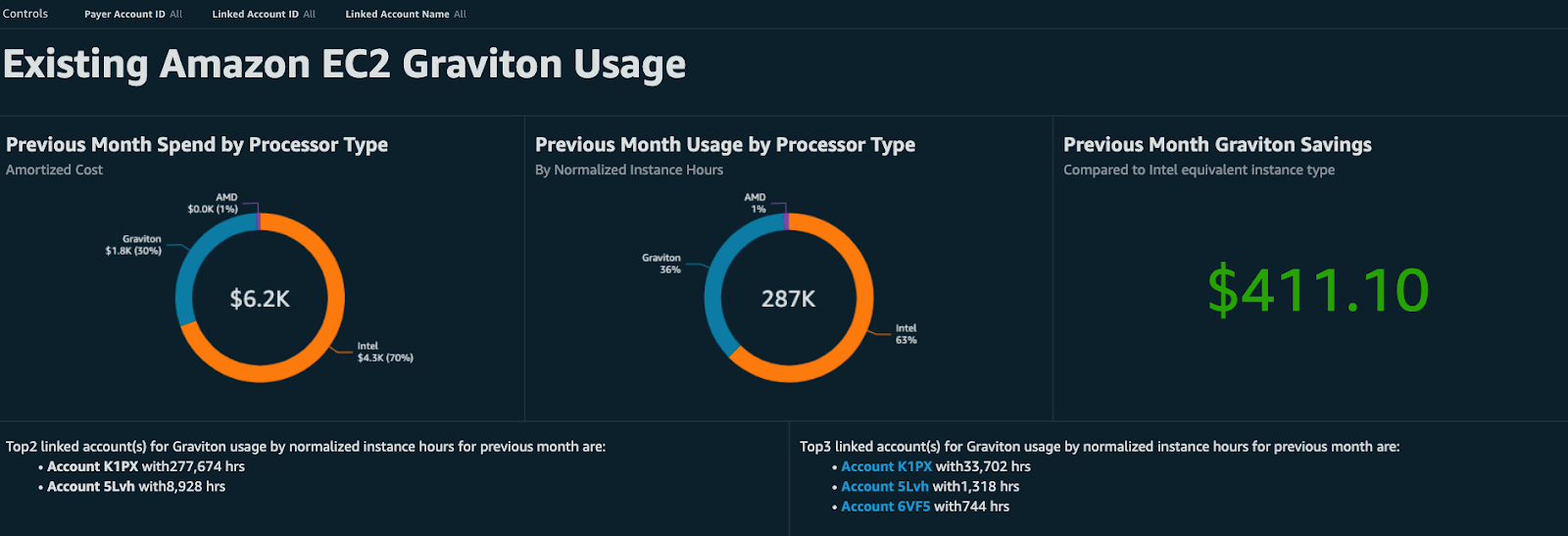
Figure 3: Graviton Savings Dashboard overview
The dashboard shows existing usage and can be used to identify more workloads that would benefit from a migration to AWS Graviton, as shown in the following figure. These workloads can either reside in other AWS Accounts of your organization or might be related to other services that support AWS Graviton, such as Amazon Relational Database Service (Amazon RDS), Amazon OpenSearch, or Amazon ElastiCache.
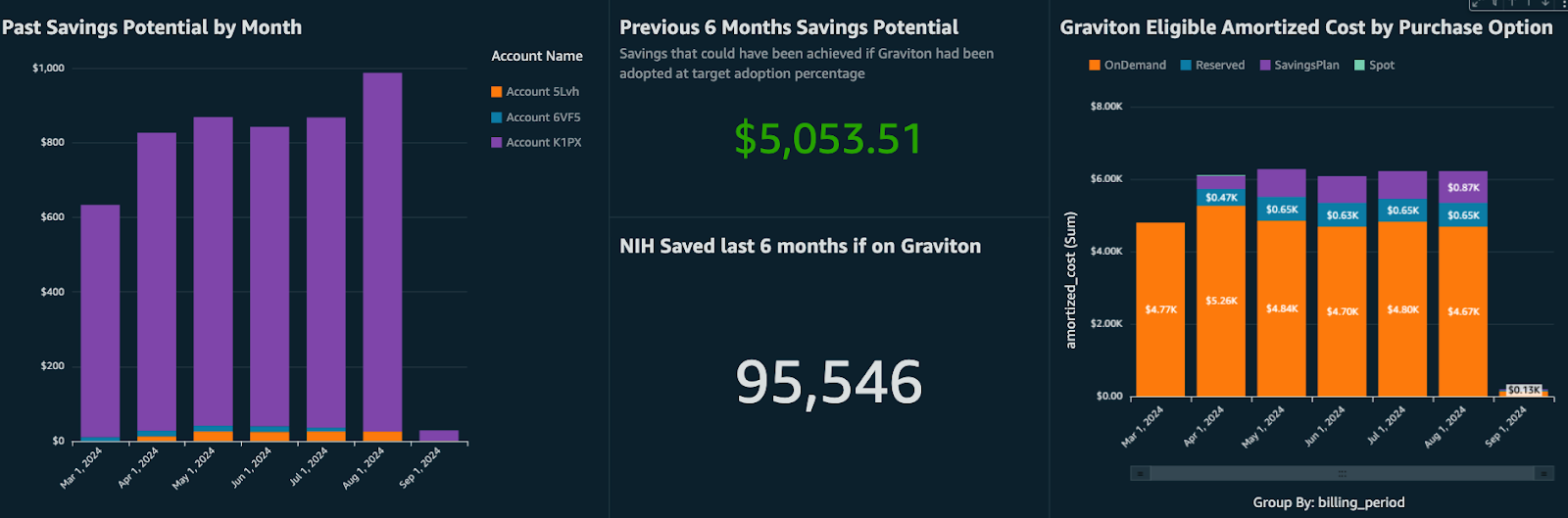
Figure 4: Graviton Savings Dashboard potential
You can deploy the Graviton Savings Dashboard to your own AWS account by following this step-by-step guide.
Conclusion
In this post, you have explored the strategies and best practices for migrating your containerized workloads to AWS Graviton. From building multi-architecture container images to using Karpenter for node provisioning and gradual rollout, you now have the knowledge and tools for a successful migration. As with any migration, the process needs careful planning and execution.
To get started, review the Graviton Savings Dashboard to identify the services and workloads in your organization that can benefit the most. Begin with low-risk test services, then gradually expand to your larger, more critical workloads. Use the guidance and examples provided in this post and the hands-on migration workshop to streamline the migration process and long-term success.