A few months back, Redis launched the Redis Vector Library (RedisVL) to simplify development of AI apps. Since then, we’ve introduced powerful new features and functionality that support Large Language Models (LLMs) at scale. RedisVL is a dedicated Python client library for using Redis for AI.
As of redisvl>=0.3.0, you get:
- Streamlined tools to build GenAI apps with our benchmark-leading vector database
- LLM memory to store and retrieve chat history
- Semantic caching to save on LLM costs and accelerate responses
- Semantic routing to send user requests to the best tool, model, or knowledge base
RedisVL extends the world’s fastest vector database
For devs building GenAI apps, we made RedisVL to abstract and simplify many of the components that you need to build modern AI apps. Redis is known for speed and simplicity, and we continue to build on that for the GenAI era. Our vector database is the fastest of any we tested, but we also want to make it simple to build with. We find that devs have to wade through many AI tools and write custom code to get those tools to work together. With RedisVL, we provide an opinionated set of commands that lets you focus on your app, so you can build faster.
Remember context from chats with LLM memory
The Problem
LLMs are inherently stateless. They don’t remember prior interactions. And we don’t just mean previous conversations, even the most recent prompt that you just gave them is immediately forgotten. With most online chatbots, you can ask follow-up questions, like, “Tell me more about that”, or, “Can you elaborate?” without issue. The reason is that a solution is to provide the full chat history with each subsequent query. This ensures that the LLM has the necessary context to respond.
When building your own LLM app, this conversation session management becomes your responsibility to handle. For this, Redis has created chat session managers in RedisVL.
The simplest approach to handling chat sessions is to keep a running list of your conversations’ back and forth exchanges, appending to it each time and passing the entire conversation history in each subsequent prompt. This contextualizes your query so the LLM always has the full context of what you’re asking about.

This works just like you would expect, but the approach becomes less efficient as conversations grow longer. Larger queries that keep appending to an ever-growing chat history result in increased costs due to higher token counts and longer compute times. Imagine having to recite your entire conversation word-for-word every time you ask a question. You probably don’t need the full conversation history attached to every new prompt, just the important parts of it.
But how do you know which parts are important?
There’s also a phenomenon in LLMs known as “information loss in the middle,” where LLMs are less adept at extracting relevant information from the middle of text blocks compared to the beginning or end. Passing large contexts with superfluous information can degrade the quality of your app. So how do you pass only the parts of your conversation history that are relevant?
The Solution
The solution is to use contextual chat history and only pass the parts of the conversation that are semantically related to your new prompt on each turn. By leveraging semantic similarity, we can determine which sections of the conversation are most relevant to the current query. This method reduces token counts, leading to cost and time savings, and likely results in better answers since only relevant context is included. We can quantify semantic similarity between a user query and sections of conversation history by leveraging text embedding models to encode text into vectors and then use Redis vector similarity search to find those vectors most similar to our latest prompt.
With RedisVL (version >= 0.3.0), you can implement this advanced solution seamlessly. RedisVL allows for efficient management of chat history by selecting the most relevant context from the session, ensuring optimal performance and cost-effectiveness. It does this through the power of a super fast vector database.

Here’s what this system looks like in code:
For a more detailed code example, visit our LLM session management recipe in the AI resources repo.
As the field evolves, so do the solutions. By continually refining our approach to contextual memory, we will push the boundaries of what’s possible with LLMs using RedisVL.
Reduce LLM costs and lag with semantic caching
The Problem
How many of your app users ask the same question? And how many of them ask the same question over and over? The answer is probably quite a few. That’s why FAQs exist for many systems. So how should LLM apps handle these questions? Right now they’re probably going through the motions of computing the same response over and over again each time. Doing essentially the same work and producing the same result each time. If this seems wasteful, it’s because it is.
The Solution
There’s more we can do to improve the performance of LLM systems. Caching has long been used as a technique in software engineering to quickly retrieve a recently calculated result from an intermediary cache layer, rather than go directly to a database to run potentially slow or complex queries. This same approach to making apps more performant can be applied to LLM apps as well. If the same question is being asked of an LLM over and over, then it makes sense to return a cached response instead of calling a costly model to provide the same answer over and over. But not all prompts will be identical, and doing exact character matching on sentences is unlikely to result in a cache hit. We need a way to compare prompts that are asking the same question, but in slightly different ways. For this we have semantic caching.
Semantic caching utilizes text embedding models to convert each query into a high-dimensional vector. This vector is the numerical representation of the query and can be used to compare the semantic meaning of sentences. Using Redis’ vector database we store pairs of user queries and LLM responses, and on each new query perform a vector similarity search to find semantically similar questions that we already have the answer to. Questions like, “Who is the king of England?”, and “Who is the United Kingdom’s monarch?” are semantically the same.
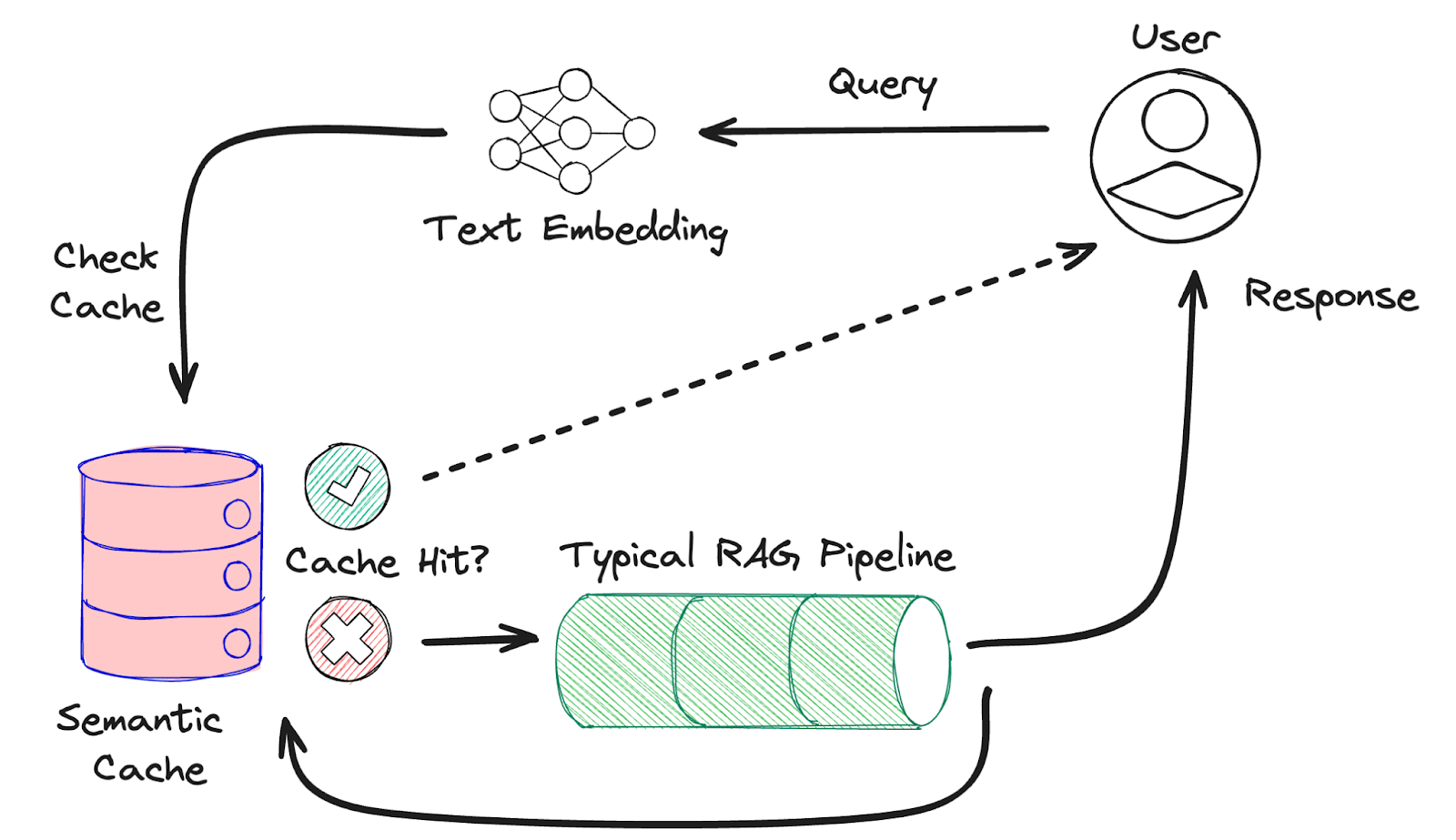
On each successful cache hit, we can directly return the cached response and bypass calls to the LLM entirely. When a genuinely novel query comes in and there’s no matching cache entry we call the LLM as normal. Either way, the user gets a clear LLM response. Just don’t forget to add this new response to your cache for next time.
Let’s take a look at how that works in code. Below is a barebones example of what it may look like to add semantic caching with RedisVL to your LLM workflow. First, here’s a simple chat loop that just sends off a query and prints the response using OpenAI.
Now let’s include a Redis semantic cache.
Ultra fast, in-memory databases can serve responses in fractions of the time that an LLM would take to respond. They can also drastically reduce your financial costs of hosting and calling LLMs.
The benefits of semantic caching can be substantial. Every cache hit is one less call to your LLM. This saves costs, but also time, as LLM response times are often measured in seconds, while cache lookups can be done in milliseconds. Research has already shown that over 30% of user questions are semantically similar to previous questions and can be served from a cache. This only accounts for questions from users. If you chose to pre-fetch FAQs into your semantic cache this hit rate could go up even more and lead to even more speedups and savings.
If you’re thinking about user privacy, and you should be thinking about user privacy, RedisVL has you covered. It enables full control of who has access to which cache entries. You can manage multiple users and conversations seamlessly with tags, or attach tool-call data too for your agentic workflows.
Select the best tool for the job with semantic routing
The Problem
Memory can be thought of as more than just storage of information. There’s also a component of working memory that allows us to direct incoming queries to different areas. While LLMs are powerful, they can sometimes be overkill for certain applications. For broad apps that have only one or a few entry points, incoming requests can vary substantially and don’t necessarily need to hit the LLM. Having one general-purpose LLM system can be sub-optimal and there can be significant benefits in routing traffic to customized LLMs, smaller LLMs, or different applications or subroutines entirely. Let’s be real, some questions really should just point the user to your FAQs, product manuals, docs, scraped web data, or connect them to your support team. Others should be rejected entirely.
The Solution
Depending on the request, users could be routed to different applications or have some default responses returned. The challenge then becomes identifying where and how to route traffic.
Importantly, this is different from a cache that sits within an LLM system as it is defined by the app developers, can lead to different application calls, and can act as a gate or guardrail to prevent unwanted queries from continuing to the LLM. The solution is semantic routing, where we can once again use the power of vector databases to measure semantic similarity of queries.
This is how we updated RedisVL to provide a semantic router to handle these cases. With a semantic router you can direct unstructured user requests to any predefined routes. One common use case is to work as guardrails at the front of LLM apps to ensure unwanted user queries get filtered out immediately.

Let’s take a peek at how this code could look. We’ll start by defining the routes we want and what queries could lead to each one.
Now we can create the semantic router with our defined routes and connect it to our Redis instance.
The last step is to call the router with a query and see where it sends us.
Let’s start building
To learn more about using Redis for AI, try out these tools in your own RAG apps. Check out the links to our GitHub repos below (give us a star!), and be sure to try our RAG workbench, where you can customize your own RAG application over your own data using RedisVL.