 11 months ago
50
11 months ago
50
Geographical redundancy is one of the keys to designing a resilient data lake architecture in the cloud. Some of the use cases for customers to replicate data geographically are to provide for low-latency reads (where data is closer to end users), comply with regulatory requirements, colocate data with other services, and maintain data redundancy for mission-critical apps.
BigQuery already stores copies of your data in two different Google Cloud zones within a dataset region. In all regions, replication between zones uses synchronous dual writes. This ensures in the event of either a soft (power failure, network partition) or hard (flood, earthquake, hurricane) zonal failure, no data loss is expected, and you will be back up and running almost immediately.
We are excited to take this a step further with the preview of cross-region dataset replication, which allows you to easily replicate any dataset, including ongoing changes, across cloud regions. In addition to ongoing replication use cases, you can use cross-region replication to migrate BigQuery datasets from one source region to another destination region.
How does it work?
BigQuery provides a primary and secondary configuration for replication across regions:
- Primary region: When you create a dataset, BigQuery designates the selected region as the location of the primary replica.
- Secondary region: When you add a dataset replica in a selected region, BigQuery designates this as a secondary replica. The secondary region could be a region of your choice. You can have more than one secondary replica.
The primary replica is writeable, and the secondary replica is read-only. Writes to the primary replica are asynchronously replicated to the secondary replica. Within each region, the data is stored redundantly in two zones. Network traffic never leaves the Google Cloud network.
While replicas are in different regions, they do not have different names. This means that your queries do not need to change when referencing a replica in a different region.
The following diagram shows the replication that occurs when a dataset is replicated:
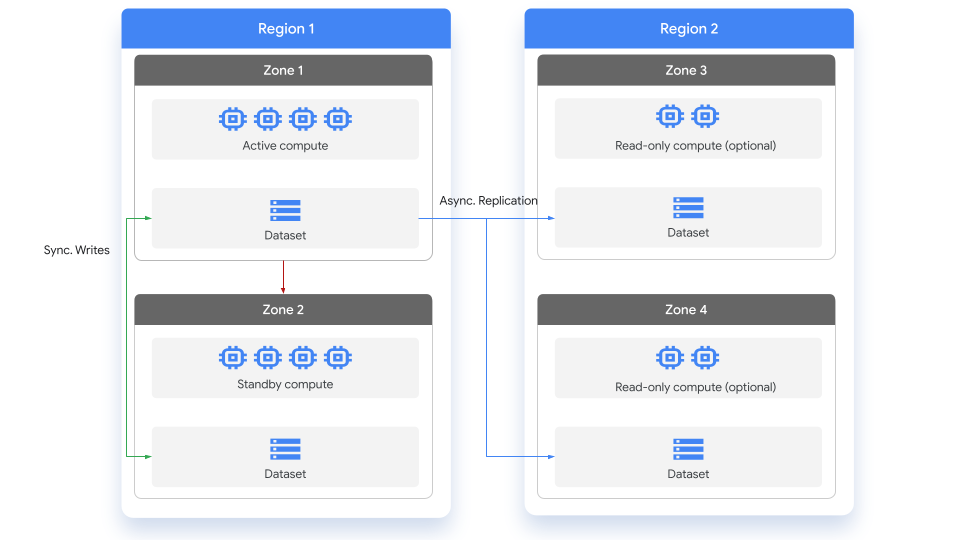
Replication in action
The following workflow shows how you can set up replication for your BigQuery datasets.
Create a replica for a given dataset
To replicate a dataset, use the ALTER SCHEMA ADD REPLICA DDL statement.
You can add a single replica to any dataset within each region or multi-region. After you add a replica, it takes time for the initial copy operation to complete. You can still run queries referencing the primary replica while the data is being replicated, with no reduction in query processing capacity.
To confirm the status that the secondary replica has successfully been created, you can query the creation_complete column in the INFORMATION_SCHEMA.SCHEMATA_REPLICAS view.
Query the secondary replica
Once initial creation is complete, you can run read-only queries against a secondary replica. To do so, set the job location to the secondary region in query settings or the BigQuery API. If you do not specify a location, BigQuery automatically routes your queries to the location of the primary replica.
If you are using BigQuery’s capacity reservations, you will need to have a reservation in the location of the secondary replica. Otherwise, your queries will use BigQuery’s on-demand processing model.
Promote the secondary replica as primary
To promote a replica to be the primary replica, use the ALTER SCHEMA SET OPTIONS DDL statement and set the primary_replica option. You must explicitly set the job location to the secondary region in query settings.
After a few seconds, the secondary replica becomes primary, and you can run both read and write operations in the new location. Similarly, the primary replica becomes secondary and only supports read operations.
Remove a dataset replica
To remove a replica and stop replicating the dataset, use the ALTER SCHEMA DROP REPLICA DDL statement. If you are using replication for migration from one region to another region, delete the replica after promoting the secondary to primary. This step is not required, but is useful if you don't need a dataset replica beyond your migration needs.
Getting started
We are super excited to make the preview for cross-region replication available for BigQuery, which will allow you to enhance your geo-redundancy and support region migration use cases. Looking ahead, we will include a console-based user interface for configuring and managing replicas. We will also offer a cross-region disaster recovery (DR) feature that extends cross-region replication to protect your workloads in the rare case of a total regional outage. You can also learn more about BigQuery and cross-region replication in the BigQuery cross-region dataset replication QuickStart.