AI is increasingly becoming a centerpiece of software development - many companies are integrating it throughout their DevSecOps workflows to improve productivity and increase efficiency. Because of this now-critical role, AI features should be tested and analyzed on an ongoing basis. In this article, we take you behind the scenes to learn how GitLab's Test Platform team does this for GitLab Duo features by conducting performance validation, functional readiness, and continuous analysis across GitLab versions. With this three-pronged approach, GitLab aims to ensure that GitLab Duo features are performing optimally for our customers.
Live demo! Discover the future of AI-driven software development with our GitLab 17 virtual launch event. Register today!
AI and testing
AI's non-deterministic nature, where the same input can produce different outputs, makes ensuring a great user experience a challenge. So, when we integrated AI deep into the GitLab DevSecOps Platform, we had to adapt to our best practices to address this challenge.
The Test Platform team's mission is to help enable the successful development and deployment of high-quality software applications with continuous analysis and efficiency to help ensure customer satisfaction. The key to achieving this is by delivering tools that help increase standardization, repeatability, and test consistency.
Applying this to GitLab Duo, our AI suite of tools to power DevSecOps workflows, means being able to continuously analyze its performance and identify opportunities for improvement. Our goal is to gain clear, actionable insights that will help us to enhance GitLab Duo's capabilities and, as a result, better meet our customers' needs.
The need for continuous analysis of AI
To continuously assess GitLab Duo, we needed a mechanism for analyzing feature performance across releases. Therefore, we created an AI continuous analysis tool to automate the collection and analysis of data to achieve this.
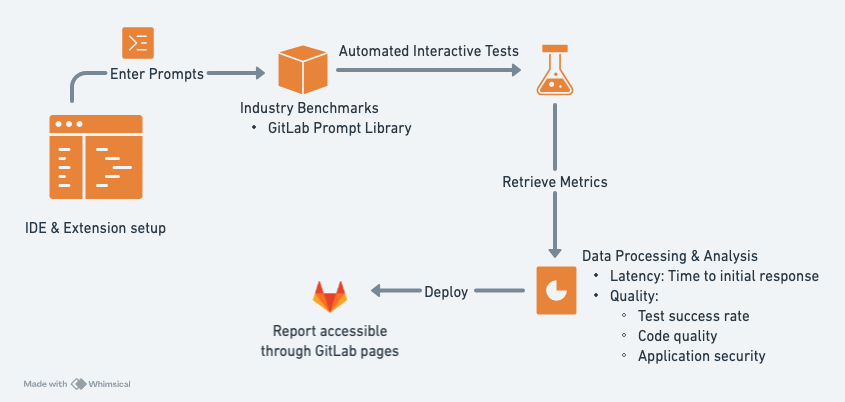
<center><i>How the AI continuous analysis tool works</i></center>
Building the AI continuous analysis tool
To gain detailed, user-centric insights, we needed to gather data in the appropriate context – in this case, the integrated development environment (IDE), as it is where most of our users access GitLab Duo. We narrowed this down further by opting for the Visual Studio Code IDE, a popular choice within our community. Once the environment was chosen, we automated entering code prompts and recording the provided suggestions. The interactions with the IDE are handled by the WebdriverIO VSCode service, and CI operations are handled through GitLab CI/CD. This automation significantly scaled up data collection and eliminated repetitive tasks for GitLab team members. To start, we have focused on measuring the performance of GitLab Duo Code Suggestions, but plan to expand to other GitLab AI features in the future.
Analyzing the data
At the core of our AI continuous analysis tool is a mechanism for collecting and analyzing code suggestions. This involves automatically entering code prompts, recording the suggestions provided, and logging timestamps of relevant events. We measure the time from when the tool provides an input until a suggestion is displayed in the UI. In addition, we record the logs created by the IDE, which report the time it took for each suggestion response to be received. With this data, we can compare the latency of suggestions in terms of how long it takes the backend AI service to send a response to the IDE, and how long it takes for the IDE to display the suggestion for the user. We then can compare latency and other metrics of GitLab Duo features across multiple releases. The GitLab platform has the ability to analyze code quality and application security, so we leverage these capabilities to enable the AI continuous analysis tool to analyze the quality and security of the suggestions provided by GitLab Duo.
Improving AI-driven suggestions
Once the collected data is analyzed, the tool automatically generates a single report summarizing the results. The report includes key statistics (e.g., mean latency and/or latency at various percentiles), descriptions of notable differences or patterns, links to raw data, and CI/CD pipeline logs and artifacts. The tool also records a video of each prompt and suggestion, which allows us to review specific cases where differences are highlighted. This creates an opportunity for the UX researchers and development teams to take action on the insights gained, helping to improve the overall user experience and system performance.
The tool is at an early stage of development, but it's already helped us to improve the experience for GitLab Duo Code Suggestions users. Moving forward, we plan to expand our tool’s capabilities, incorporate more metrics and consume and provide input to our Centralized Evaluation Framework, which validates AI models, to enhance our continuous analysis further.
Performance validation
As AI has become integral to GitLab's offerings, optimizing the performance of AI-driven features is essential. Our performance tests aim to evaluate and monitor the performance of our GitLab components, which interact with AI service backends. While we can monitor the performance of these external services as part of our production environment's observability, we cannot control them. Thus, including third-party services in our performance testing would be expensive and yield limited benefits. Although third-party AI providers contribute to overall latency, the latency attributable to GitLab components is still important to check. We aim to detect changes that might lead to performance degradation by monitoring GitLab components.
Building AI performance validation test environment
In our AI test environments, the AI Gateway, which is a stand-alone service to give access to AI features to GitLab users, has been configured to return mocked responses, enabling us to test the performance of AI-powered features without interacting with third-party AI service providers. We conduct AI performance tests on reference architecture environments of various sizes. Additionally, we evaluate new tests in their own isolated environment before they're added to the larger environments.
Testing multi-regional latency
Multi-regional latency tests need to be run from various geolocations to validate that requests are being served from a suitable location close to the source of the request. We do this today with the use of the GitLab Environment Toolkit. The toolkit provisions an environment in the identified region to test (note: both the AI Gateway and the provisioned environment are in the same region), then uses the GitLab Performance Tool to run tests to measure time to first byte (TTFB). TTFB is our way of measuring time to the first part of the response being rendered, which contributes to the perceived latency that a customer experiences. To account for this measurement, our tests have a check to help ensure that the response itself isn't empty.
Our tests are expanding further to continue to measure perceived latency from a customer’s perspective. We have captured a set of baseline response times that indicate how a specific set of regions performed when the test environment was in a known good state. These baselines allow us to compare subsequent environment updates and other regions to this known state to evaluate the impact of changes. These baseline measurements can be updated after major updates to ensure they stay relevant in the future.
Note: As of this article's publication date, we have AI Gateway deployments across the U.S., Europe, and Asia. To learn more, visit our handbook page.
Functionality
To help continuously enable customers to confidently leverage AI reliably, we must continuously work to ensure our AI features function as expected.
Unit and integration tests
Features that leverage AI models still require rigorous automated tests, which help engineers develop new features and changes confidently. However, since AI features can involve integrating with third-party AI providers, we must be careful to stub any external API calls to help ensure our tests are fast and reliable.
For a comprehensive look at testing at GitLab, look at our testing standards and style guidelines.
End-to-end tests
End-to-end testing is a strategy for checking whether the application works as expected across the entire software stack and architecture. We've implemented it in two ways for GitLab Duo testing: using real AI-generated responses and mock-generated AI responses.
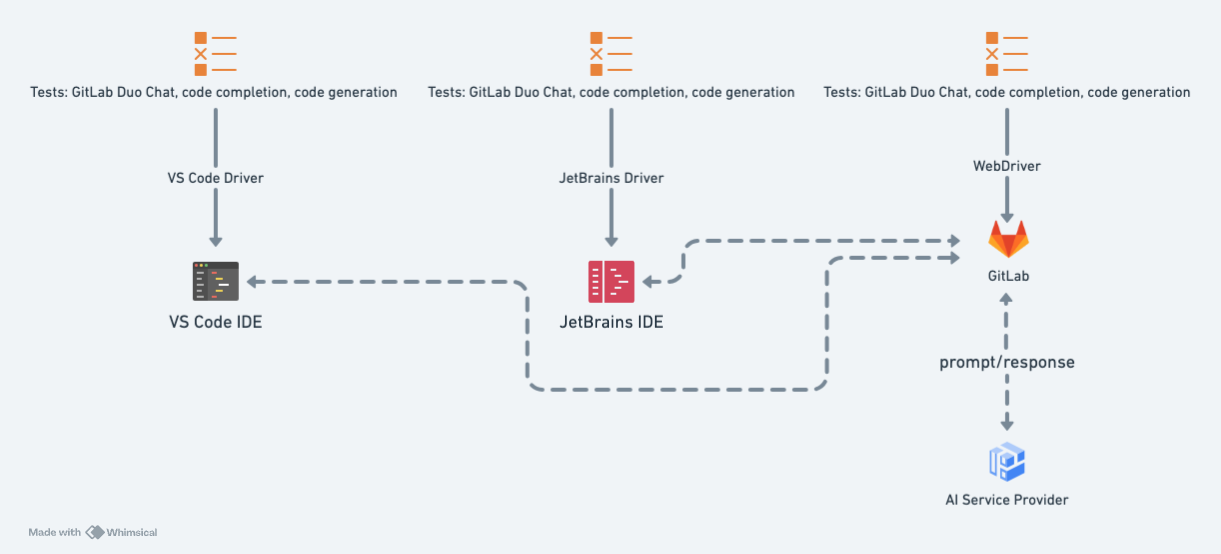
<center><i>End-to-end test workflow</i></center>
Using real AI-generated responses
Although costly, end-to-end tests are important to help ensure the entire user experience functions as expected. Since AI models are non-deterministic, end-to-end test assertions for validating real AI-generated responses should be loose enough to help ensure the feature functions without relying on a response that may change. This might mean an assertion that checks for some response with no errors or for a response we are certain to receive.
AI-driven functionality is not accessible only from within the GitLab application, so we must also consider user workflows for other applications that leverage these features. For example, to cover the use case of a developer requesting code suggestions in IntelliJ IDEA using the GitLab Duo plugin, we need to drive the IntelliJ application to simulate a user workflow. Similarly, to ensure that the GitLab Duo Chat experience is consistent in VS Code, we must drive the VS Code application and exercise the GitLab Workflow extension. Working to ensure these workflows are covered helps us maintain a consistently great developer experience across all GitLab products.
Using mock AI-generated responses
In addition to end-to-end tests using real AI-generated responses, we run some end-to-end tests against test environments configured to return mock responses. This allows us to verify changes to GitLab code and components that don’t depend on responses generated by an AI model more frequently.
For a closer look at end-to-end testing, read our end-to-end testing guide.
Exploratory testing and dogfooding
AI features are built by humans for humans. At GitLab, exploratory testing and dogfooding greatly benefit us. GitLab team members are passionate about what features get shipped, and insights from internal usage are invaluable in shaping the direction of AI features.
Exploratory testing allows the team to creatively exercise features to help ensure edge case bugs are identified and resolved. Dogfooding encourages team members to use AI features in their daily workflows, which helps us identify realistic issues from realistic users. For a comprehensive look at how we dogfood AI features, look at Developing GitLab Duo: How we are dogfooding our AI features.
Get started with GitLab Duo
Hopefully this article gives you insight into how we are validating AI features at GitLab. We have integrated our team's process into our overall development as we iterate on GitLab Duo features. We encourage you to try GitLab Duo in your organization and reap the benefits of AI-powered workflows.
Start a free trial of GitLab Duo today!
Members of the GitLab Test Platform team contributed to this article.