 11 months ago
46
11 months ago
46
The Service Intelligence team here at Wayfair is responsible for maintaining multiple machine learning models that continuously improve Wayfair’s customer service experience. For example, we are providing our support staff with new capabilities such as predicting a customer’s intent or calculating the optimal discount to offer for a damaged item. Historically, most of our models have made batch predictions which were then cached for online serving. In 2023 we moved our models from batch inference to real-time inference, and in doing so we wanted to design an architecture that would allow us to deploy and serve real-time models safely, effectively, and efficiently.
Wayfair already has an in-house solution for real-time model serving, but our team appreciates the simplicity and ease of use offered by Vertex AI prediction endpoints. One feature that is important to us is that the creation and deletion of Vertex AI endpoints can be automated in code, something that is more challenging with our in-house solution.
To facilitate the rapid deployment of new models, we require that all models be registered in MLflow, as this allows us to take advantage of the uniform interface MLflow provides. We follow an infrastructure-as-code paradigm by storing the desired state of all deployed models in a GitHub repository.

An abbreviated example of the configuration information stored in the repository.
Storing the configuration in a GitHub repository allows us to track version history and to enforce governance via GitHub’s pull request approval process. Approved changes to the configuration trigger a Buildkite CI/CD pipeline that performs the tasks listed below:
Calculate the delta between the current and desired state of deployed endpoints
- For each new or updated model:
Pull model metadata and artifacts from MLflow
Package the model into a custom container and upload it to theArtifact Registry
Create an endpoint and deploy the custom container to that endpoint
Load test the endpoint
Create alert policies for the endpoint inCloud Monitoring
Upload model metadata and desired traffic splitting toCloud Bigtable
- Deleteendpoints that are no longer needed
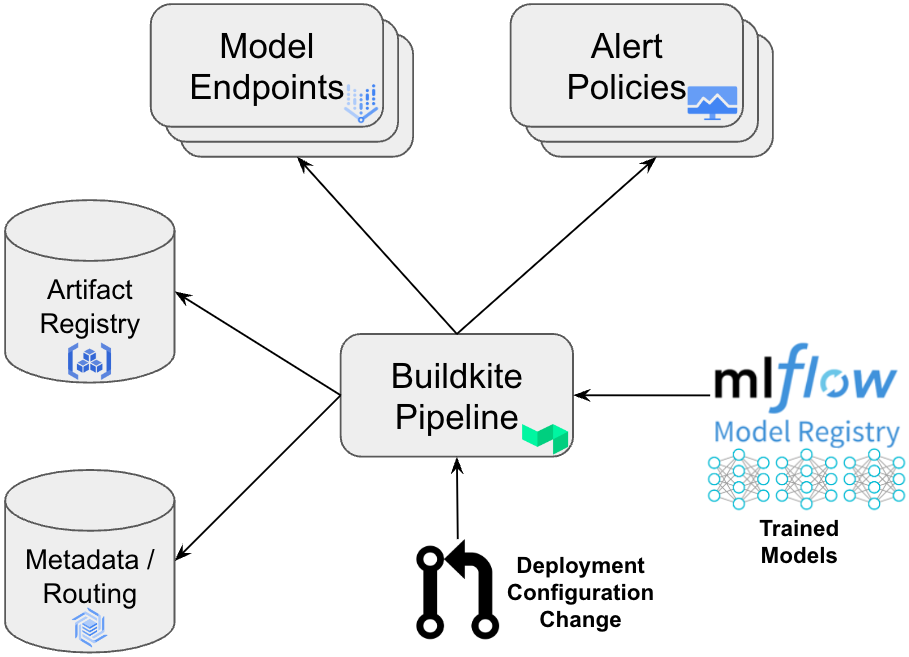
A visualization of the automated steps taken by the Buildkite pipeline that is triggered when a configuration change is pushed to the repository.
Downstream applications that wish to interact with the real-time endpoints do so by sending requests to a model controller service running in Google Kubernetes Engine. The model controller is responsible for handling cross-cutting concerns such as reading model metadata and routing information from Cloud Bigtable, fetching features from the Vertex AI Feature Store, splitting traffic (e.g., A/B tests, shadow mode) between endpoints, and logging model predictions to BigQuery.

A visualization of our real-time model serving architecture.
We have made notable improvements to how fast we can deploy new AI models thanks to Vertex AI. In the past, getting a new real-time model up and running took around a month of work. Now, thanks to automating our processes with Vertex AI and a streamlined deployment architecture, we have cut that down to just one hour.
By turning previously manual steps into automated ones, we supercharged our productivity and developer velocity, while ensuring critical details do not get missed. Load testing, alert setup, and other “optional” tasks are now baked right into the process.
The authors thank Anh Do and Sandeep Kandekar from Wayfair for their technical contributions, and Neela Chaudhari, Kieran Kavanagh, and Brij Dhanda from Google for their support with Google Cloud.