 11 months ago
90
11 months ago
90
In the ever-evolving landscape of machine learning, efficient model management is critical. This is especially true for the realm of fraud detection, where the models have to be redeployed frequently as they act against human adversaries, who can reverse-engineer fraud model logic and adapt their tactics accordingly.
Within one of the world’s leading local delivery platforms Delivery Hero, the Incentive Fraud team is responsible for building ML-powered, rule-based services for detecting and preventing abuse of incentive vouchers. For example, these vouchers can be granted to newly registered users to motivate them to use the food delivery platform, so it should be possible to reliably identify the genuinely new customers from those creating new accounts for each order. This task becomes especially challenging given that Delivery Hero operates in 70+ countries, each imposing various data protection regulations that often have different local constraints.
Tech setup
Model Serving Overview
At a high level, the team’s setup is a REST API service, implementing rule-based logic on top of the decisions provided by a set of interconnected ML models. The setup has tight latency restrictions as the API is called on each food order request. To achieve those latency requirements, the service and the models run in regional Kubernetes clusters with horizontal autoscaler and other high-availability practices.
The diagram below shows the high-level model serving architecture:
- The blue path shows the pre-computing of several ML-based features produced by other models and storing results in cache.
- The red path shows the actual fraud detection request, which first aggregates the information related to the order and user and then makes a request to the main fraud detection model, and processes the result according to the rule-based configurable logic.

The team chose Vertex AI for its ML model development environment for its scalability and tight integration with BigQuery — the primary data warehouse at Delivery Hero — and other Google Cloud services. The models are trained in Vertex AI Pipelines which stores their metadata in Vertex AI Model Registry. Once trained and analyzed, the models are built into a FastAPI docker image by Cloud Build.
CI/CD for ML
In order to enable fast iterations of the model development, all workflows were deeply integrated with GitHub Actions CI/CD, thus allowing users to train models and build images while following software engineering and MLOps best practices:
- Version Control (VC) - all changes tracked for both model and data sides (data is passed to Vertex Pipelines as a snapshot of a BigQuery table stored on GCS as a set of parquet files, with parameter `DATASET_VERSION` as a suffix).
- Continuous Integration (CI) - reliable trunk-based development in a GitHub repository submitting workflows to shared GCP Vertex AI environments without a need to trigger the pipelines from the local machine. As a result, the users (data scientists) can run experiments right within the Pull Requests (PR) with explicit experiment tracking.
- Continuous Deployment (CD) - enabling users to release new models to production confidently and independently without much assistance from the engineering side (“Friday night release”).
- Continuous Testing (CT) - visibility of model quality metrics and artifacts lineage integrated with CI/CD for better collaboration between data scientists , ML engineers , stakeholders, and decisionmakers.
One of the reasons for implementing CT for the models was the need to enable the development and maintenance of the multiple models trained while sharing the same code base but being trained on different subsets of data. A typical example within Delivery Hero is to maintain tens of models, one per country, and deploy them in a regional cluster (EMEA, APAC, etc.). Thus, the decision on each model has to be taken individually, however, the development, evaluation and sometimes deployment iterations are shared across the models.
Implementation details
For the Incentive Fraud use-case, it was possible to implement such ML Operations workflows using the GCP Vertex AI Model Registry at the backend, with the use of an internal Python package ml-utils developed by the team. This package provides a single CLI or Python API interface to link together the entities of Kubeflow pipelines (used internally by GCP Vertex AI Pipelines): Pipelines (or Pipeline Runs), Experiments (grouping of the pipelines), and Models and Datasets (output artifacts of the pipelines). Internally, ml-utils loads the large json definitions of the Kubeflow Pipeline Runs, finds the required artifacts and downloads them in a pre-defined format. More importantly, it provides an abstraction layer to the Models enforcing naming conventions, and provides functionality to query the Vertex ML Metadata in order to search for the models by wildcards.
The picture below illustrates the use of the described CI/CD workflow based on Vertex AI with the use of the custom tool ml-utils:

As shown in the picture above, each commit the user creates in the GitHub repo triggers a set of training pipelines in Vertex AI, one for each country. Some of the pipelines might fail (marked as red), and some succeed (green).
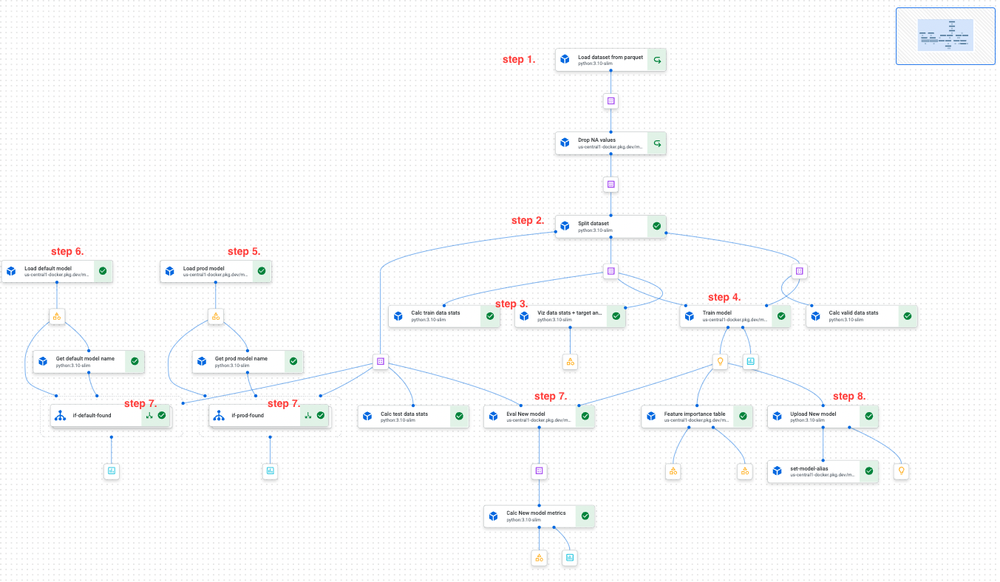
Steps of the Vertex AI training pipeline (see screenshot below):
- load the specified dataset snapshot from GCS,
- split data to train/test/validation,
- calculate the dataset properties (statistics and visualization, data drift, etc.),
- train a new model,
- load the model currently deployed to production (using ml-utils),
- load the “champion model” (best-ever model according to some specified metrics) (using ml-utils),
- evaluate all three models against the same test dataset split and save the evaluation metrics in Vertex AI Model Registry - as Experiment metadata, to be retrieved using ml-utils,
- upload the new model to the Vertex AI Model Registry, and update its aliases:
- an alias containing git commit hash: `pr123-a1b2c3d` for a PR commit or `main-a1b2c3d` for a main branch commit,
- if the model outperforms the champion model, move the `champ` alias to it.
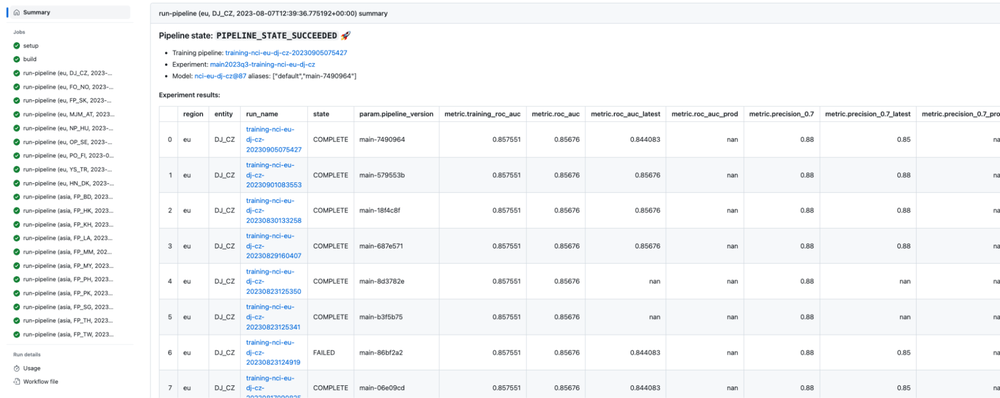
All the artifacts of the pipeline (data slices, models, etc.) are automatically saved to GCS. Once all the Vertex AI pipelines have succeeded, the GitHub Actions job that had triggered the pipelines, uses ml-utils to query the Vertex AI Model Registry to retrieve the evaluation metrics and print them as markdown to the GitHub Actions job Summary page for visibility (see picture below). Thus, each git commit is linked to a set of Vertex pipelines and to the model quality report, which is used by data scientists and managers to make decisions after interpreting the models' quality.
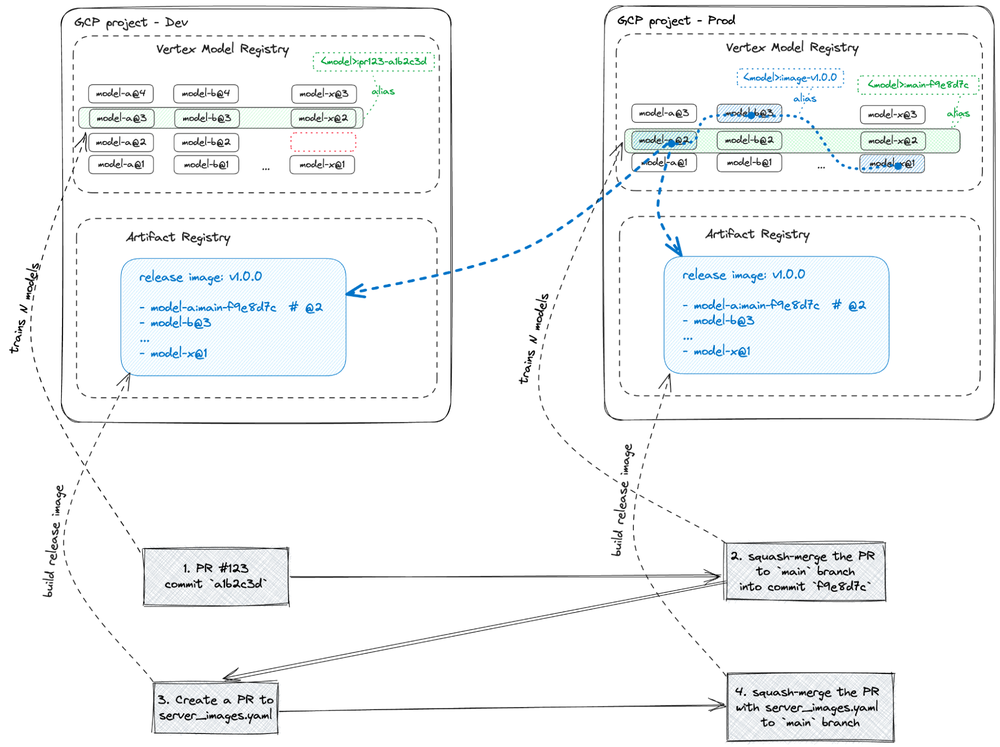
Once the team is ready to redeploy some of the models, they create a PR to modify the serving image config, which defines the slice of the models to be deployed to production. This is the blue dashed line in Vertex Model Registry. This PR triggers another GitHub Actions workflow that submits a Cloudbuild workflow, which loads the specified model pickles, builds the FastAPI server image with the models baked in it, runs integration tests, and updates the aliases of the models (adds the alias “image-{imagetag}”).
Below is the screenshot of GitHub Actions page with model training Summary page for one of the models:
Infrastructure overview
For the Incentive Fraud projects, the team used two environments:
- Dev - an environment with relaxed security restrictions used to experiment on the models and run end-to-end (e2e) tests of the model training pipelines.
- Prod - an environment with hardened security restrictions for producing model release candidates.
To facilitate work with the two projects, the team implemented five high-level rules:
- GitHub Actions running GCP workflows in Dev and Prod environments act exactly the same.
- Each PR commit triggers GCP workflows in Dev environment.
- Each main branch commit triggers GCP workflows in Prod environment.
- Both Dev and Prod pipelines use the same code and dataset snapshots.
- Each PR is first squashed into a single commit before being merged into the main branch.
These rules allow the team to have a clean linear history of the main branch, where each commit, if it changes model code, dataset version or configuration, builds a set of per-country release candidate models with expected quality metrics:
Results
As a result, the described MLOps setup has allowed the team to accomplish the KPIs of drastically reducing the time model server release time from days to one hour by automating the whole process and implementing software engineering and MLOps best practices.
Specifically, the team was able to:
- Confidently scale models to 20+ countries in 2 global regions.
- Have full trackability in git and model lineage in Vertex AI.
- Perform “time travel” (experiment with new model code running on older dataset snapshots).
- Implement proper pipeline caching for cost optimization.
- Fully automate training, batch scoring pipelines, as well as model analysis notebooks, and model deployment workflows.
- Effectively achieve MLOps level 2 with full CI/CD pipeline automation, source control, and deployment processes.
Achievement highlights:
- The solution is collaboratively used by 20+ developers, data scientists, and managers.
- End-to-end ML cycle reduced from a few days to four hours.
- Solution used over 10 months of usage (as of October 2023).
- Implemented for 2 different ML use cases.
- 150+ feature Pull Requests, averaging 5 PRs per week.
- Over 20 fully automated deployments for each project, averaging 2 deployments per month.
- Resulted in a 70% reduction in voucher fraud.
If you want to learn more about how Delivery Hero built a BigQuery powered data mesh, achieving data democratization across the company and accelerating data-driven solutions, read the case study.