 5 months ago
48
5 months ago
48
See how Dynatrace can quickly find which machines are being impacted.
Security vendor CrowdStrike released an update to their popular platform early on July 19, 2024, ultimately producing an issue that caused many Windows-based machines to fail, resulting in a BSOD (Blue Screen of Death). The global impact has affected almost every major industry, resulting in closed bank branches, ground stops on flights, failures for retail point-of-sale devices, and, unfortunately, much more. Many organizations struggle to determine the extent of the issue, and where dependencies exist with those impacted machines.
How Dynatrace quickly finds machines affected by the CrowdStrike issue
The Dynatrace observability and security platform quickly allows you to understand what is running within your environment. Dynatrace does this by automatically creating a dependency map of your IT ecosystem, pinpointing the technologies in your stack and how they interact with each other, including servers, processes, application services, and web applications across data centers and multicloud environments. The Dynatrace platform establishes context across all observability data sources – metrics, events, logs, traces, user sessions, synthetic probes, runtime security vulnerabilities, and more.
For the CrowdStrike issue, one can use both monitored Windows System logs and the Dynatrace entity model to find out what servers are impacted. The following is an example of a query using the Dynatrace Query Language (DQL) to find out when BSOD issues are being written to Windows System logs.
fetch logs | filter contains(content,"bugcheck",caseSensitive:false) | filter dt.process.name == "Windows System" | lookup [ fetch dt.entity.process_group_instance | fieldsAdd host_id=belongs_to[dt.entity.host] | fieldsAdd pgi_name = entity.name ], sourceField:dt.process.name, lookupField:pgi_name, prefix:"process." | parse content, """LD 'bugcheck was: ' LD:bug_hex_details' (' LD EOF""" | lookup [ fetch dt.entity.host | fieldsAdd host_name = entity.name | fieldsAdd monitoringMode ], sourceField:process.host_id, lookupField:id, prefix:"host." | fieldsAdd bsod_type= if(contains(bug_hex_details,"14f"), "SDBUS_INTERNAL_ERROR",else: if(contains(bug_hex_details,"3b"), "SYSTEM_SERVICE_EXCEPTION",else: if(contains(bug_hex_details,"9f"), "DRIVER_POWER_STATE_FAILURE",else: if(contains(bug_hex_details,"133"), "DPC_WATCHDOG_VIOLATION",else: if(contains(bug_hex_details,"50"), "PAGE_FAULT_IN_NONPAGED_AREA",else: if(contains(bug_hex_details,"d1"), "DRIVER_IRQL_NOT_LESS_OR_EQUAL",else:"" )))))) | limit 10000 | filter isNotNull(bug_hex_details) | fields timestamp, `Windows Log Event ID`=winlog.eventid, `Windows Record ID`=RecordID, `BSOD Bug Hex Code`=bug_hex_details, `BSOD Type`=bsod_type, `Host`=host.host_name
The following query uses the Dynatrace entity model to grab all CrowdStrike processes, giving the host names affected and the process count, giving the host names affected and whether those servers were restarted in the last 24 hours, allowing you to prioritize your remediation efforts.
fetch dt.entity.process_group_instance | fieldsAdd pgi_name=entity.name | filter contains(pgi_name,"crowdstrike",caseSensitive:false) | lookup [ fetch dt.entity.process_group_instance | fieldsAdd host_id=belongs_to[dt.entity.host] | fieldsAdd runs | fieldsAdd metadata | fieldsAdd isDockerized | fieldsAdd awsNameTag | fieldsAdd pgi_id = id | fieldsAdd inbound_pgi=toString(called_by) | fieldsAdd outbound_pgi=toString(calls) | fieldsAdd pgi_name = entity.name ], sourceField:pgi_name, lookupField:pgi_name, prefix:"process." | lookup [ fetch dt.entity.host | fieldsAdd host_name = entity.name | fieldsAdd monitoringMode | fieldsAdd osType | fieldsAdd lifetime ], sourceField:process.host_id, lookupField:id, prefix:"host." | fieldsAdd starttime=toLong(toTimestamp(lifetime[start])) | filter host.osType=="WINDOWS" // Determine whether the server has been restarted in the last 24 hrs | fieldsAdd recent_restart_24hr = toLong(toTimestamp(now())) - starttime | fieldsAdd recent_restart=if(recent_restart_24hr<24*60*60*1000000000,"YES",else:"NO") // Add in field to check for Bitlocker-related processes | lookup [ fetch dt.entity.process_group_instance | fieldsAdd host_id=belongs_to[dt.entity.host] | filter contains(entity.name,"bitlocker",caseSensitive:false) | fieldsAdd pgi_name = entity.name ], sourceField:process.host_id, lookupField:host_id, prefix:"bitlocker." | limit 10000 // Apply filters | fieldsAdd `Bitlocker Present?`=if(isNotNull(bitlocker.pgi_name),"YES",else:"NO") | fields `Host`=host.host_name, `Process Name`=pgi_name, `Host Link`=host_link, `Recently Restarted?`=recent_restart, `Bitlocker Present?` | summarize count=count(), by:{`Host`, `Bitlocker Present?`, `Recently Restarted?`} | sort `Bitlocker Present?` asc | fields `Host`, `Bitlocker Present?`, `Recently Restarted?`, `Host Link`Here are the results of this query, placed on a Dynatrace third-generation dashboard you can filter based on host name and whether the hosts were recently restarted.
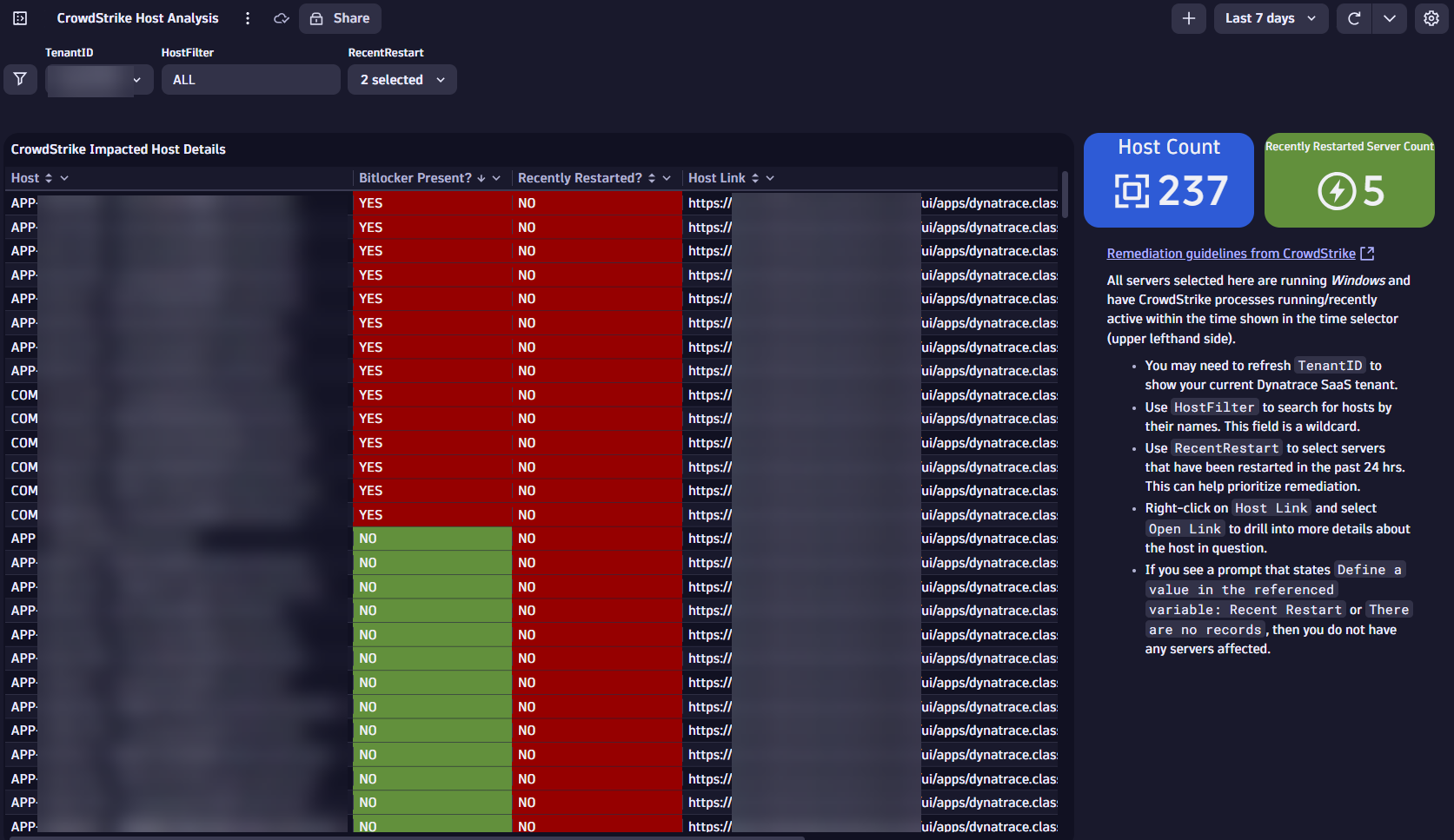
By having this visibility within a moment’s notice, you can quickly understand the extent of the problem. This allows you to save time and money by better directing your limited resources to focus on where the problem is impacting your most critical business systems.
You can download the CrowdStrike Host Analysis dashboard from this Github repository: Dynatrace CrowdStrike Dashboard
What do I need to get the CrowdStrike BSOD detection to work?
By using capabilities like Dynatrace Discovery and Foundation mode and Dynatrace Log ingest, you can understand the extent to which an issue like this CrowdStrike problem exists within your environments in minutes.
CrowdStrike BSOD issue FAQ for Dynatrace customers
Here’s what else you need to know about the CrowdStrike BSOD issue.
Q: What is the CrowdStrike issue?
A: On July 19th, 2024, Cybersecurity company CrowdStrike rolled out an update to an endpoint security protection solution that contained a defect in the version that updated Windows-based systems. This defect led to widespread system crashes of Windows servers protected by CrowdStrike, which caused global service outages across industries, including airlines, banks, and public sector entities.
Q: What was the cause of the outage?
A: CrowdStrike issued an update for Windows PCs that contained a defect. Affected servers were forced into a boot loop, which prevented them from turning on. The boot sequence is the initial turn-on process of a server, where operating systems, applications, and services running on the server are initially brought online.
Q: Why has this been such a severe outage?
A: Once an affected server is stuck in a boot loop, it is unable to set up communications and services, meaning that it won’t respond to any requests or commands. It is as if the server is turned off. To restore services, remediation must be accomplished individually and manually. The remediation process can also be complex and time-consuming for each server and may involve a “rollback” to a previous point in time from backup copies.
Q: Is there a timeline for restoring services?
A: Since remediation is manual and time-consuming, restoring services will depend on prioritizing which servers are involved in the most critical applications and prioritizing those above less critical services. This can take hours or days for many organizations. Dynatrace customers can hasten this process by quickly finding affected hosts and prioritizing the most critical ones first.
Q: How is Dynatrace helping our customers who are impacted by the outage?
A: While remediation of this issue must be accomplished through manual intervention, the Dynatrace platform will identify which servers are impacted. Dynatrace Smartscape technology understands precisely which services each server is associated with and, therefore, simplifies the process for customers to establish plans and restore servers and services associated with their most critical applications.
Q: Are many Dynatrace customers impacted by the outage?
A: Yes, as this outage was unavoidable once CrowdStrike pushed the defective update out, and many of the world’s largest and most important enterprises have standardized on CrowdStrike for endpoint protection and Dynatrace for observability. Fortunately, Dynatrace is helping our customers rapidly identify and prioritize impacted servers so they can quickly restore services to their most critical business functions. By knowing exactly which offline servers are associated with specific critical business services and the exact dependency relationships that exist, IT teams can rapidly establish plans to manually remediate in an efficient way to restore business-critical functions.
Dynatrace customers are well accustomed to this process as they use it when zero-day runtime vulnerabilities such as Log4Shell are discovered that immediately present a threat to large swaths of their environment. In those vulnerability cases, Dynatrace helps customers immediately prioritize affected code; for instance, prioritizing patching of code that is exposed to the internet over code libraries that are not accessed at all and, therefore, pose no security risk.
Q: Do we help with our customers’ entire environments?
A: Unfortunately, Smartscape only covers hosts that are targeted by the Dynatrace platform. If Smartscape isn’t monitoring parts of the environment, it won’t be included in the Dynatrace entity model. Customers are increasingly targeting their entire environments by taking advantage of Foundation and Discovery mode, which is a cost-effective way to provide end-to-end coverage of their entire IT landscape.
Q: Were Dynatrace services impacted by the outage?
A: No. Dynatrace services were not impacted directly. However, communication between monitored hosts and Dynatrace may have been interrupted due to interactions between the monitored host and non-Dynatrace systems that were affected by the outage.