Editor's note: From time to time, we invite members of our partner community to contribute to the GitLab Blog. Thanks to Gufran Yeşilyurt, a DevOps consultant at OBSS Technology, for co-creating with us.
This tutorial will walk you through setting up an MLOps pipeline with GitLab Model Registry, utilizing MLflow. This will be a great starting point to manage your ML apps entirely through GitLab. But first, it is crucial to understand why we need MLOps and what GitLab offers.
MLOps, or machine learning operations, is a critical practice for managing and automating the lifecycle of machine learning models, from development to deployment and maintenance. Its importance lies in addressing the complexity and dynamism of machine learning workflows, which involve not just software development but also data management, model training, testing, deployment, and continuous monitoring.
MLOps ensures that models are reproducible, scalable, and maintainable, facilitating collaboration between data scientists, machine learning engineers, and operations teams. By incorporating MLOps, organizations can streamline the deployment process, reduce time to market, and improve the reliability and performance of their machine learning applications.
The necessity of MLOps arises from the unique challenges posed by machine learning projects. Unlike traditional software development, machine learning involves handling large datasets, experimenting with various models, and continuously updating models based on new data and feedback.
Without proper operations, managing these aspects becomes cumbersome, leading to potential issues like model drift, where the model's performance degrades over time due to changes in the underlying data. MLOps provides a structured approach to monitor and manage these changes, ensuring that models remain accurate and effective. Moreover, it introduces automation in various stages, such as data preprocessing, model training, and deployment, thereby reducing manual errors and enhancing efficiency.
GitLab's features play a pivotal role in implementing MLOps effectively. GitLab provides an integrated platform that combines source code management, CI/CD pipelines, tracking and collaboration tools, making it ideal for managing machine learning projects.
With GitLab, teams can leverage version control to track changes in both code and data, ensuring reproducibility and transparency. The CI/CD pipelines in GitLab automate the testing and deployment of machine learning models, allowing for continuous integration and continuous delivery. This automation not only speeds up the deployment process but also ensures consistency and reliability in the models being deployed.
Additionally, GitLab's collaboration features, such as merge requests and code reviews, facilitate better communication and coordination among team members, ensuring that everyone is aligned and any issues are promptly addressed.
Prerequisites:
- basic knowledge of GitLab pipelines
- basic knowledge of MLflow
- a Kubernetes cluster
- Dockerfile
This tutorial includes instructions to:
- Set up environment variables of MLflow
- Train and log candidates at merge request
- Register the most successful candidate
- Dockerize and deploy an ML app with the registered model
In this example, to decide whether to provide the user a loan, we make use of Random Forest Classifier, Decision Tree, and Logistic Regression. At the end of this showcase, we will have a web application that utilizes machine learning to respond to the user.
To reproduce this example in your own GitLab environment, you can read the rest of this article or follow the video below. You can find the source code of this example in these OBSS repositories.
Set up environment variables of MLflow
On the host where the code is executed, set the environment variables for tracking URI and token. This might be a remote host, CI pipeline, or your local environment. When they are set, you can call mlflow.set_experiment("<experiment_name>"). As a reference:
export MLFLOW_TRACKING_URI="<your gitlab endpoint>/api/v4/projects/<your project id>/ml/mlflow" export MLFLOW_TRACKING_TOKEN="<your_access_token>"Note: If the training code contains the call to mlflow.set_tracking_uri(), remove it.
Train and log candidates at merge request
In your model train code, you can use MLflow methods to log metrics, artifacts, and parameters. You can also divide the train steps into pipeline stages if you are comfortable with that part. In this example, one Python file will be used for both training and report generation.
mlflow.log_params(params) mlflow.log_metrics(metrics_data) mlflow.log_artifact(artifacts)You can then create the necessary pipeline to train the experiment. By adding the relevant rules, you can trigger this pipeline manually in merge requests and observe the report generated as MR Note.
When the pipeline is finished, you can see the details about the candidate in Analyze > Model Experiments.
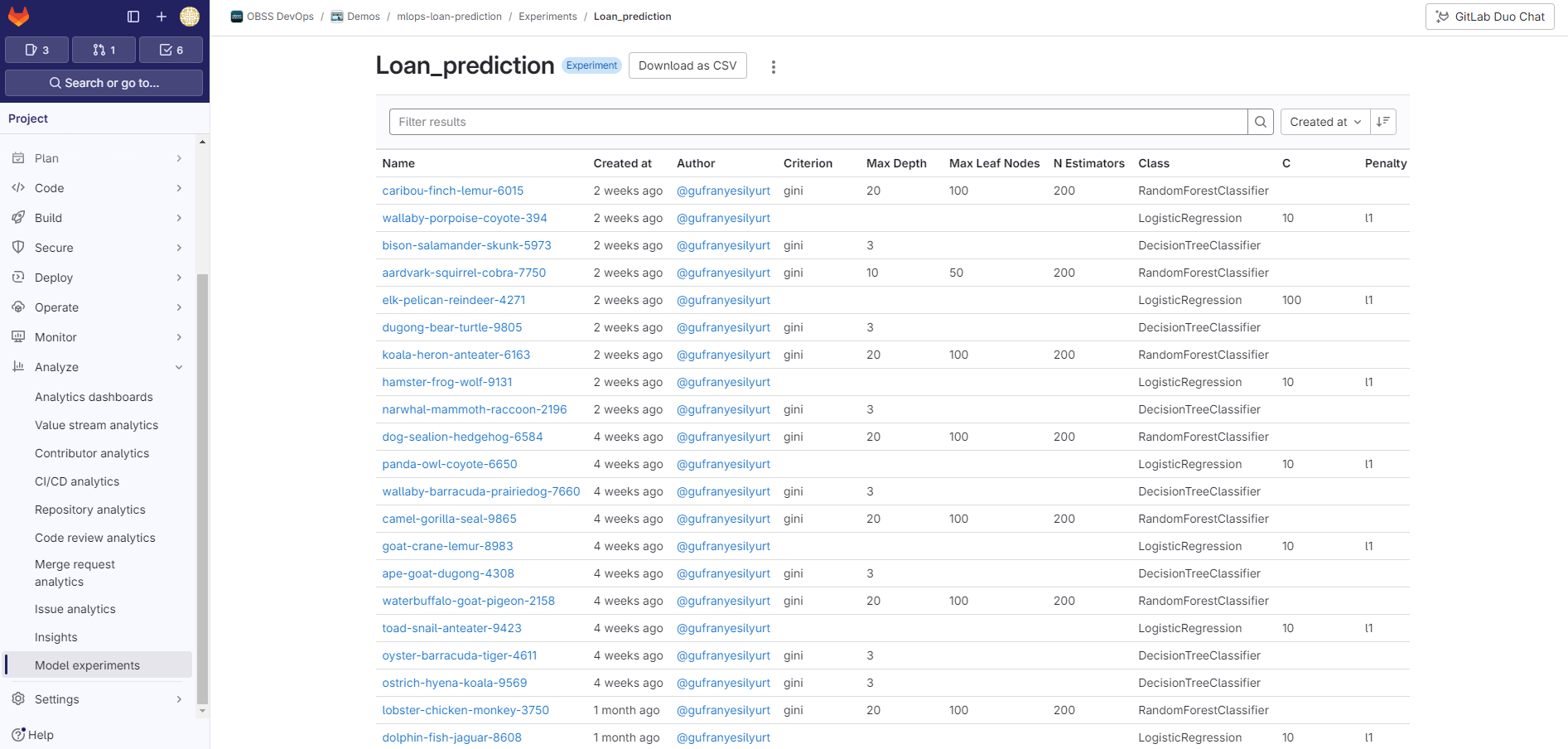
Register the most successful candidate
According to the measurements you have made, we can register the most successful candidate (may be the one with the highest accuracy value) with the Run ID of the candidate.
But first, we need to create a model and its version in Registry. I created these steps in separate stages and components (because I may need these steps in other projects). You should be careful to use semantic versioning when versioning.
Register source model parameters and metrics
source_candidate = client.get_run(source_candidate_id) params = { k: v for k, v in source_candidate.data.params.items() } metric = { k: v for k, v in source_candidate.data.metrics.items() } model_version = client.get_model_version(model_name, version) run_id = model_version.run_id model_class = "" for name, value in params.items(): client.log_param(run_id, name, value) if name == "Class": model_class = value for name, value in metric.items(): client.log_metric(run_id, name, value)After logging the parameters and metrics, you can register the artifacts as you did in the train step.
You may want to manually enter the inputs of the relevant steps as a variable in the pipeline.
CI/CD components
I have used CI/CD components because they provide a structured environment for managing machine learning workflows. These components enable reusability by allowing teams to store and share standardized scripts, models, and datasets, ensuring that previous work can be easily accessed, modified, and redeployed in future projects, thus accelerating development and reducing redundancy.
Learn more about CI/CD components and the CI/CD Catalog.
Dockerize and deploy an ML app with the registered model
In this project, while registering the model, I also register the pkl file as an artifact and then create the docker image with that artifact and send it to GitLab Container Registry.
You can now access your Docker image from the Container Registry and deploy it to your environment with the method you want.
Resources
- Model experiments
- MLflow client compatibility
- CI/CD components
- Building GitLab with GitLab: Why there is no MLOps without DevSecOps
Credits: This tutorial and the corresponding sample projects were created and generously shared with the community by OBSS. OBSS is an EMEA-based channel partner of GitLab. They have deep expertise across the whole DevSecOps lifecycle and amongst many other things, they are more than happy to support customers with migrating their MLOps workloads to GitLab.