 10 months ago
152
10 months ago
152
Introduction
If you're looking to transform the way you interact with unstructured data, you've come to the right place! In this blog, you'll discover how the exciting field of Generative AI, specifically tools like Vector Search and large language models (LLMs), are revolutionizing search capabilities.
You will learn the power of vector search and additionally, you will explore techniques for rapid ingestion of unstructured data, such as web pages, to enhance your search and chat systems efficiently.
A typical conversational search solution for querying public pages involves the following steps:
- Crawl and load web pages content: Extract and organize web page content for further processing.
- Create document chunks and vector embeddings: Divide web page content into smaller segments and generate vector representations of each chunk.
- Store document chunks and embeddings in a secure location: Securely store text chunks and vector embeddings for efficient retrieval.
- Build a vector search index to store the embeddings for later querying: Construct a Vector Search index to efficiently search and retrieve vector embeddings based on similarity.
- Continuously update the vector search index with new page contents: Regularly update the index with new web page content to maintain relevance.
- Perform search queries on the vector search index to retrieve relevant web page content: Leverage the vector search index to identify and retrieve relevant web page content in response to search queries.
Maintaining the data ingestion process over time can be daunting, especially when dealing with thousands of web pages.
Fear not, we've got your back.
Our solution
We streamline the data ingestion process, making it effortless to deploy a conversational search solution that draws insights from the specified webpages. Our approach leverages a combination of Google Cloud products, including Vertex AI Vector Search, Vertex AI Text Embedding Model, Cloud Storage, Cloud Run, and Cloud Logging.
Benefits:
- Easy deployment: Guided steps ensure seamless integration into your Google Cloud project.
- Flexible configuration: Customize project, region, index-prefix, index, and endpoint names to suit your needs.
- Real-time monitoring: Cloud Logging provides comprehensive visibility into the data ingestion pipeline.
- Scalable storage: Cloud Storage securely stores text chunks and embeddings for efficient retrieval.
Reference architecture

Steps
1. Enable APIs
Enable the following APIs either using the Google Cloud console or using the below gcloud commands
2. Clone repository
Under this repository you will find an application written in python using the fastapi framework with a single REST endpoint exposed which will take care of the steps detailed in the introduction. More information on the application can be found on its README.md file.
3. Set project and region in DockerFile
After downloading the github repo, open it in any supported text editor of your choice. Edit the Dockerfile and update the REGION and PROJECT_ID values of your preference.
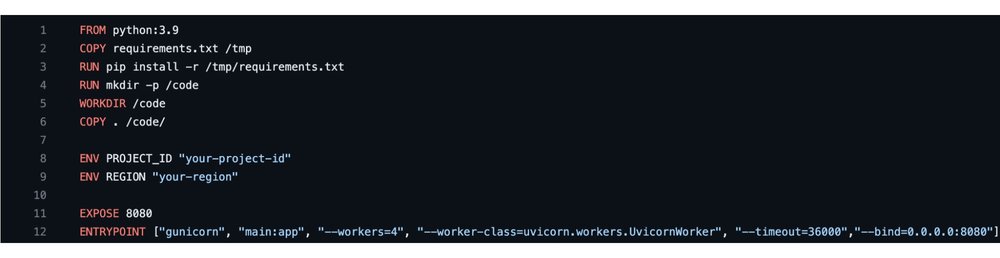
4. Build image and deploy Cloud Run app
5. Call endpoint to create index
To begin loading the public website’s content into an index endpoint on GCP, call the http post endpoint with required configuration parameters in the body.
- Index_name => str : This parameter will match your index and indexEndpoint DisplayName and your GCS Bucket.
In case a GCS Bucket with that name doesn't exist a new one will be created, as well as a new index.
In case the GCS Bucket name isn't universally unique, the method will return 400. - Url => str : The URL which content is going to be embedded. URL must end in sitemap.xml, method will return 400 otherwise.
- Prefix_name => str : It will be used as a tag on Cloud log, to track the progress of your job, as well as to create a folder inside your GCS Bucket, which will later on store the embeddings.
Below is an example of calling the endpoint using the CuRL command.
6. Check Cloud Logging for progress
Once you've initiated index creation using the provided CuRL command, you can monitor the ingestion process's progress by utilizing Cloud Logging and filtering logs based on the specified prefix name.

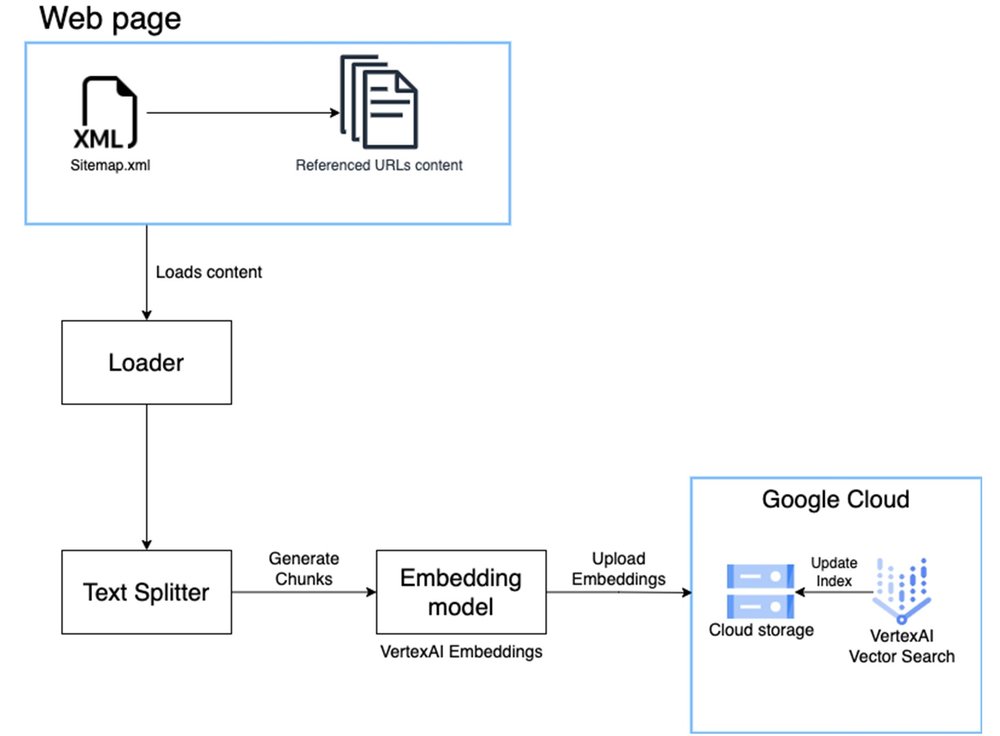
Data pipeline
The data pipeline is built in order to simplify the process of extracting, chunking and embedding creation. Here is a detailed diagram of the pipeline. We make use of Langchain libraries to load and split web data. Refer to the code for more details.
7. Query index to get search results
After the pipeline completion, approximately 3-4 hours depending on the website ingested, you’ll have an index and an index endpoint created in your Google Cloud project and you can find them under the Vector Search option in Vertex AI.
You can now query the index endpoint using the match function of the vector search Python library.
Reference code below on how to query an existing vector search index endpoint.

Conclusion
To further enhance the solution's efficiency, you can implement parallel processing to simultaneously ingest large websites or multiple websites, significantly reducing the overall data consumption time.
After the creation of index endpoint, you can now develop a generative AI application that leverages the vector search index to identify the closest matches, and employs a text generation model to contextualize and provide answers to our queries. To learn more about this exciting topic check out this blog.