 1 month ago
18
1 month ago
18
The rise of large-scale AI models capable of processing diverse modalities like text and images presents a unique infrastructural challenge. These models require immense computational power and specialized hardware to efficiently handle training, fine-tuning, and inference. Over a decade ago, Google began developing custom AI accelerators, Tensor Processing Units (TPUs), to address the growing demands of AI workloads, paving the way for multimodal AI.
Earlier this year, we announced Trillium, our sixth-generation and most performant TPU to date. Today, it is generally available for Google Cloud customers.
We used Trillium TPUs to train the new Gemini 2.0, Google’s most capable AI model yet, and now enterprises and startups alike can take advantage of the same powerful, efficient, and sustainable infrastructure.
Trillium TPU is a key component of Google Cloud's AI Hypercomputer, a groundbreaking supercomputer architecture that employs an integrated system of performance-optimized hardware, open software, leading ML frameworks, and flexible consumption models. As part of the general availability of Trillium TPUs, we are also making key enhancements to AI Hypercomputer's open software layer, including optimizations to the XLA compiler and popular frameworks such as JAX, PyTorch and TensorFlow to achieve leading price-performance at scale across AI training, tuning, and serving. Additionally, features such as host-offloading using the massive host DRAM (complementing the High Bandwidth Memory, or HBM) deliver next-level efficiency. AI Hypercomputer enables you to extract maximum value from an unprecedented deployment of over 100,000 Trillium chips per Jupiter network fabric with 13 Petabits/sec of bisectional bandwidth, capable of scaling a single distributed training job to hundreds of thousands of accelerators.
Already, customers like A21 Labs are using Trillium to deliver meaningful AI solutions to their customers faster:
“At AI21, we constantly strive to enhance the performance and efficiency of our Mamba and Jamba language models. As long-time users of TPUs since v4, we're incredibly impressed with the capabilities of Google Cloud's Trillium. The advancements in scale, speed, and cost-efficiency are significant. We believe Trillium will be essential in accelerating the development of our next generation of sophisticated language models, enabling us to deliver even more powerful and accessible AI solutions to our customers." - Barak Lenz, CTO, AI21 Labs
Here are some of the key improvements that Trillium delivers over the prior generation:
-
Over 4x improvement in training performance
-
Up to 3x increase in inference throughput
-
A 67% increase in energy efficiency
-
An impressive 4.7x increase in peak compute performance per chip
-
Double the High Bandwidth Memory (HBM) capacity
-
Double the Interchip Interconnect (ICI) bandwidth
-
100K Trillium chips in a single Jupiter network fabric
-
Up to 2.5x improvement in training performance per dollar and up to 1.4x improvement in inference performance per dollar
These enhancements enable Trillium to excel across a wide range of AI workloads, including:
-
Scaling AI training workloads
-
Training LLMs including dense and Mixture of Experts (MoE) models
-
Inference performance and collection scheduling
-
Embedding-intensive models
-
Delivering training and inference price-performance
Let’s take a look at how Trillium performs for each of these workloads.
Scaling AI training workloads
Training large models like Gemini 2.0 requires massive amounts of data and computation. Trillium's near-linear scaling capabilities allow these models to be trained significantly faster by distributing the workload effectively and efficiently across a multitude of Trillium hosts that are connected through a high-speed interchip interconnect within a 256-chip pod and our state-of-the-art Jupiter data center networking. This is made possible by TPU multislice, and full-stack technology for large-scale training, and further optimized by Titanium, a system of dynamic data-center-wide offloads that range from host adapters to the network fabric.
Trillium achieves 99% scaling efficiency with a deployment of 12 pods consisting of 3072 chips, and demonstrates 94% scaling efficiency across 24 pods with 6144 chips to pre-train gpt3-175b, even when operating across a data-center network to pre-train gpt3-175b.
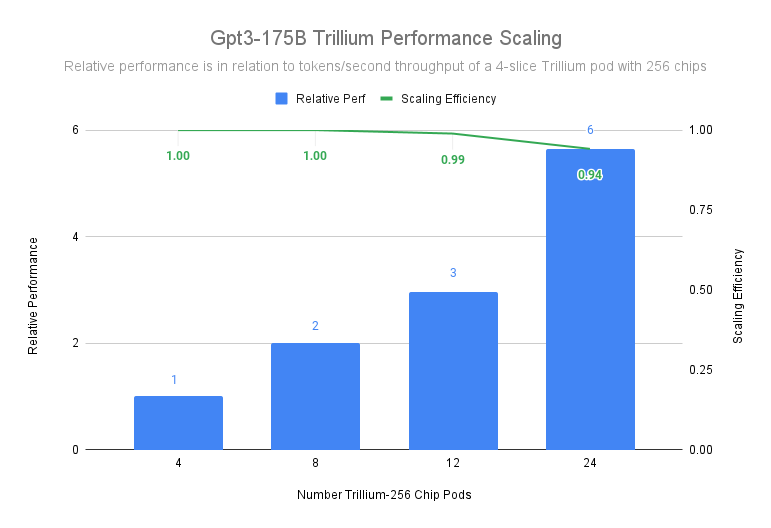
Figure 1. Source data: Google benchmark and MLPerf™ 4.1. n x Trillium-256 corresponds to n Trillium pods with 256 chips in one ICI domain
While in the graph above we use a 4-slice Trillium-256 chip pod as baseline, using a 1-slice trillium-256 chip pod as our baseline still results in over 90% scaling efficiency as you scale up to 24 pods.
When training the Llama-2-70B model, our tests demonstrate that Trillium achieves near-linear scaling from a 4-slice Trillium-256 chip pod to a 36-slice Trillium-256 chip pod at a 99% scaling efficiency.
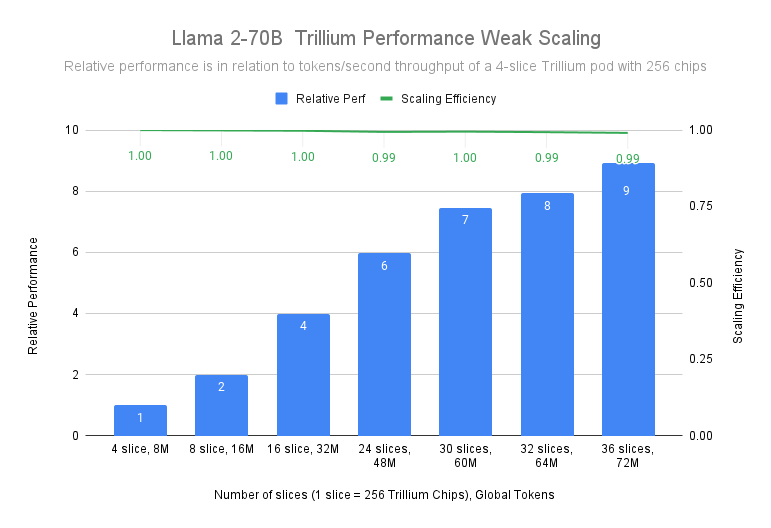
Figure 2. Source data: Google benchmark using MaxText reference implementation on 4k Seq Length. n x Trillium-256 corresponds to n Trillium pods with 256 chips in one ICI domain.
Trillium TPUs exhibit significantly better scaling efficiency compared to prior generations. In the graph below, our tests demonstrate Trillium’s 99% scaling efficiency at 12-pod scale compared to a Cloud TPU v5p cluster of equivalent scale (total peak flops).
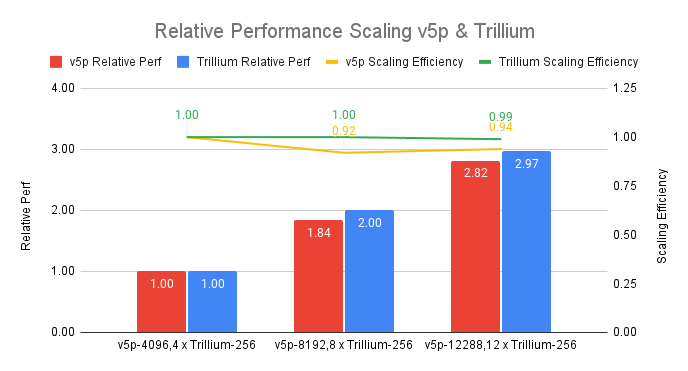
Figure 3. Source data: MLPerf™ 4.1 Training Closed results for Trillium (Preview) and v5p on GPT3-175b training task. As of November, 2024: Weak scaling comparison for Trillium and Cloud TPU v5p. v5p-4096 and 4xTrillium-256 are considered as base for scaling factor measurement. n x Trillium-256 corresponds to n Trillium pods with 256 chips in one ICI domain. v5p-n corresponds to n/2 v5p chips in a single ICI domain.
Training LLMs including dense and Mixture of Experts (MoE) models
LLMs like Gemini are inherently powerful and complex, with billions of parameters. Training such dense LLMs requires enormous computational power combined with co-designed software optimizations. Trillium delivers up to 4x faster training for dense LLMs like Llama-2-70b and gpt3-175b than the previous-generation Cloud TPU v5e.
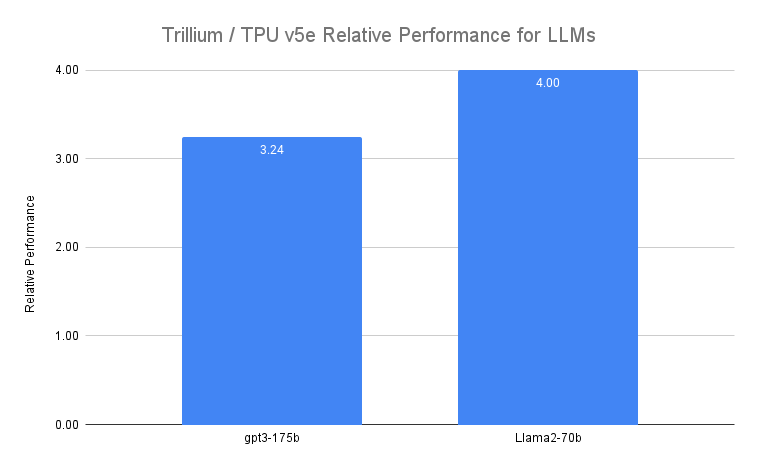
Figure 4. Source data: Google benchmark on steptime run on v5e and Trillium
In addition to dense LLMs, training LLMs with a Mixture of Experts (MoE) architecture is an increasingly popular approach, incorporating multiple "expert" neural networks, each specialized in a different aspect of an AI task. Managing and coordinating these experts during training adds complexity compared to training a single monolithic model. Trillium delivers up to 3.8x faster training for MoE models than the previous-generation Cloud TPU v5e.
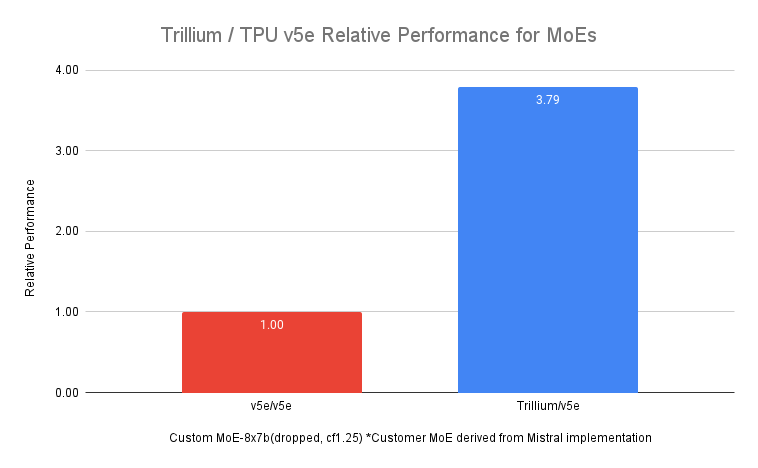
Figure 5. Source data: Google benchmark on steptime run on v5e and Trillium
Additionally, Trillium TPU offers 3x the host dynamic random-access memory (DRAM) compared to Cloud TPU v5e. This offloads some computation to the host, helping to maximize performance and Goodput at scale. Trillium’s host-offloading capabilities deliver over a 50% improvement in performance when training the Llama-3.1-405B model, as measured in Model FLOPs Utilization (MFU).
Inference performance and collection scheduling
The growing importance of multi-step reasoning at inference time necessitates accelerators that can efficiently handle the increased computational demands. Trillium provides significant advancements for inference workloads, enabling faster and more efficient AI model deployment. In fact, Trillium delivers our best TPU inference performance for image diffusion and dense LLMs. Our tests demonstrate over 3x higher relative inference throughput (images per second) for Stable Diffusion XL, and nearly 2x higher relative inference throughput (tokens per second) for Llama2-70B compared to Cloud TPU v5e.
Trillium is our highest performing TPU for both offline and server inference use cases. The graph below demonstrates 3.1x higher relative throughput (images per second) for offline inference and 2.9x higher relative throughput for server inference for Stable Diffusion XL compared to Cloud TPU v5e.
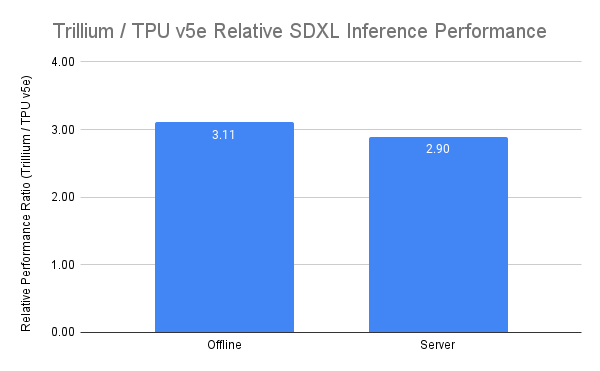
Figure 6. Source data: Google benchmark on images/second for both offline and online SDXL use cases using MaxDiffusion reference implementation.
In addition to better performance, Trillium introduces a new collections scheduling capability. This feature allows Google's scheduling systems to make intelligent job-scheduling decisions to increase the overall availability and efficiency of inference workloads when there are multiple replicas in a collection. It offers a way to manage multiple TPU slices running a single-host or multi-host inference workload, including through Google Kubernetes Engine (GKE). Grouping these slices into a collection makes it simple to adjust the number of replicas to match the demand.
Embedding-intensive models
With the addition of third-generation SparseCore, Trillium delivers a 2x improvement in the performance of embedding-intensive models and a 5x improvement in DLRM DCNv2 performance.
SparseCores are dataflow processors that provide a more adaptable architectural foundation for embedding-intensive workloads. Trillium’s third-generation SparseCore excels at accelerating dynamic and data-dependent operations, such as scatter-gather, sparse segment sum, and partitioning.
Delivering training and inference price-performance
In addition to the absolute performance and scale that is required to train some of the world’s largest AI workloads, Trillium is designed to optimize performance per dollar. To date, Trillium provides up to 2.1x increase in performance per dollar over Cloud TPU v5e and up to 2.5x increase in performance per dollar over Cloud TPU v5p in training dense LLMs like Llama2-70b and Llama3.1-405b.
Trillium excels at parallel processing of large models in a cost effective manner. It is designed to empower researchers and developers to serve robust and efficient image models at significantly lower cost than before. The cost to generate one thousand images on Trillium is 27% less than Cloud TPU v5e for offline inference and 22% less than Cloud TPU v5e for server inference on SDXL.
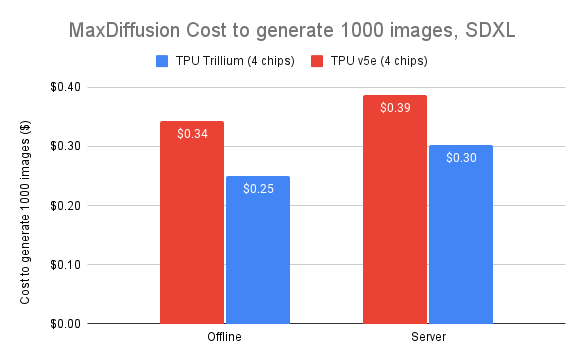
Figure 7. Source data: Google benchmark on images/second for both offline and online SDXL use cases using MaxDiffusion reference implementation.
Take AI innovation to the next level
Trillium represents a significant leap forward in Google Cloud’s AI infrastructure, delivering incredible performance, scalability, and efficiency for a wide range of AI workloads. With its ability to scale to hundreds of thousands of chips using world-class co-designed software, Trillium empowers you to achieve faster breakthroughs and deliver superior AI solutions. Furthermore, Trillium's exceptional price-performance makes it a cost-effective choice for organizations seeking to maximize the value of their AI investments. As the AI landscape continues to evolve, Trillium stands as a testament to Google Cloud's commitment to providing cutting-edge infrastructure that empowers businesses to unlock the full potential of AI.
We're excited to see how you will leverage Trillium and AI Hypercomputer to push the boundaries of AI innovation. Check out the announcement video that highlights how the Trillium system comes together to drive acceleration for your most demanding AI workloads.

To learn more about Trillium TPUs, visit g.co/tpu or contact our sales team.
Posted in