Until recently, the "files" format was the only way for Git to store references. With the release of Git 2.45.0, Git can now store references in a "reftable" format. This new format is a binary format that is quite a bit more complex, but that complexity allows it to address several shortcomings of the "files" format. The design goals for the "reftable" format include:
- Make the lookup of a single reference and iteration through ranges of references as efficient and fast as possible.
- Support for consistent reads of references so that Git never reads an in-between state when an update to multiple references has been applied only partially.
- Support for atomic writes such that updating multiple references can be implemented as an all-or-nothing operation.
- Efficient storage of both refs and the reflog.
In this article, we will go under the hood of the "reftable" format to see exactly how it works.
How Git stores references
Before we dive into the details of the "reftable" format, let's quickly recap how Git has historically stored references. If you are already familiar with this, you can skip this section.
A Git repository keeps track of two important data structures:
-
Objects, which contain the actual data of your repository. This includes commits, the directory tree structure, and the blobs that contain your source code. Objects point to each other, forming an object graph. Furthermore, each object has an object ID that uniquely identifies the object.
-
References, such as branches and tags, which are pointers into the object graph so that you can give objects names that are easier to remember and keep track of different tracks of your development history. For example, a repository may contain a main branch, which is a reference named refs/heads/main that points to a specific commit.
References are stored in the reference database. Until Git 2.45.0, there was only the "files" database format. In this format, every reference is stored as a normal file that contains either one of the following:
- A regular reference that contains the object ID of the commit it points to.
- A symbolic reference that contains the name of another reference, similar to how a symbolic link points to another file.
At regular intervals, these references get packed into a single packed-refs file to make lookups more efficient.
The following examples should give an idea of how the "files" format operates:
$ git init . $ git commit --allow-empty --message "Initial commit" [main (root-commit) 6917c17] Initial commit # HEAD is a symbolic reference pointing to refs/heads/main. $ cat .git/HEAD ref: refs/heads/main # refs/heads/main is a regular reference pointing to a commit. $ cat .git/refs/heads/main 6917c178cfc3c50215a82cf959204e9934af24c8 # git-pack-refs(1) packs these references into the packed-refs file. $ git pack-refs --all $ cat .git/packed-refs # pack-refs with: peeled fully-peeled sorted 6917c178cfc3c50215a82cf959204e9934af24c8 refs/heads/mainHigh-level structure of reftables
Assuming that you've got Git 2.45.0 or newer installed, you can create a repository with the "reftable" format by using the --ref-format=reftable switch:
$ git init --ref-format=reftable . Initialized empty Git repository in /tmp/repo/.git/ $ git rev-parse --show-ref-format reftable # Irrelevant files have been removed for ease of understanding. $ tree .git .git ├── config ├── HEAD ├── index ├── objects ├── refs │ └── heads └── reftable ├── 0x000000000001-0x000000000002-40a482a9.ref └── tables.list 4 directories, 6 filesFirst, looking at the repository configuration, you will see it has an extension.refstorage key:
$ cat .git/config [core] repositoryformatversion = 1 filemode = true bare = false logallrefupdates = true [extensions] refstorage = reftableThis configuration indicates to Git that the repository has been initialized with the "reftable" format and tells Git to use the "reftable" backend to access it.
Weirdly enough, the repository still has a few files that look as if the "files" backend was in use:
-
HEAD would usually be a symbolic reference pointing to your currently checked-out branch. While it is not used by the "reftable" backend, it is required for Git clients to detect the directory as a Git repository. Therefore, when using the "reftable" format, HEAD is a stub with contents ref: refs/heads/.invalid.
-
refs/heads is a file with contents this repository uses the reftable format. Git clients that do not know about the "reftable" format would usually expect this path to be a directory. Consequently, creating this path as a file intentionally causes such older Git clients to fail if they tried to access the repository with the "files" backend.
The actual references are stored in the reftable/ directory:
$ tree .git/reftable .git/reftable/ ├── 0x000000000001-0x000000000001-794bd722.ref └── tables.list $ cat .git/reftable/tables.list 0x000000000001-0x000000000001-794bd722.refThere are two files here:
-
0x000000000001-0x000000000001-794bd722.ref is a table containing references and the reflog data in a binary format.
-
tables.list is, well, a list of tables. In the current state of the repository, the file contains a single line, which is the name of the table. This file tracks the current set of active tables in the "reftable" database and is updated whenever new tables get added to the repository.
Updating a reference creates a new table:
$ git commit --allow-empty --message "Initial commit" [main (root-commit) 1472a58] Initial commit $ tree .git/reftable .git/reftable/ ├── 0x000000000001-0x000000000002-eb87d12b.ref └── tables.list $ cat .git/reftable/tables.list 0x000000000001-0x000000000002-eb87d12b.refAs you can see, the previous table has been replaced with a new one. Furthermore, the tables.list file has been updated to contain the new table.
The structure of a table
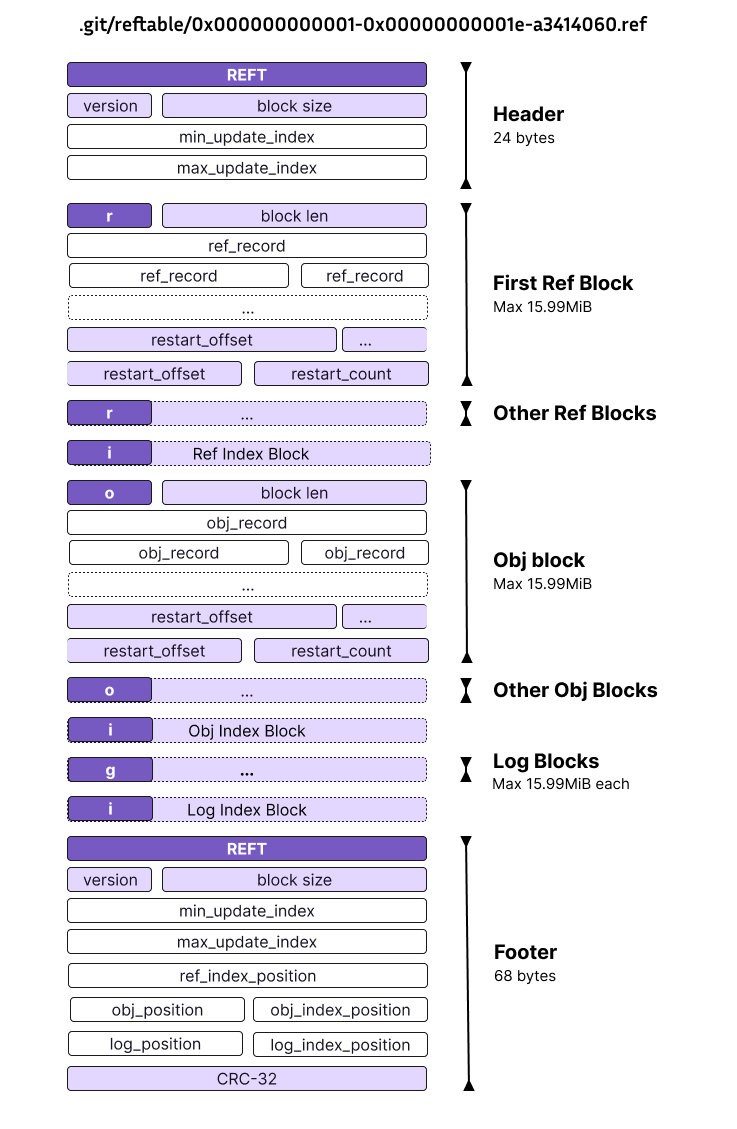
As mentioned earlier, the actual data of the reference database is contained in tables. Roughly speaking, a table is split up into multiple sections:
- The "header" contains metadata about the table. Along with some other information, this includes the version of the format, the block size, and the hash function used by the repository (for example, SHA1 or SHA256).
- The "ref" section contains your references. These records have a key that equals the reference name and point to either an object ID for regular references, or to another reference for symbolic references.
- The "obj" section contains reverse mapping from object IDs to the references that point to those object IDs. These allow Git to efficiently look up which references point to a given object ID.
- The "log" section contains your reflog entries. These records have a key that equals the reference name plus an index that represents the number of the log entry. Furthermore, they contain the old and new object IDs as well as the message for that reflog entry.
- The "footer" contains offsets to the various sections.
Each of the section types are structured in a similar manner. Sections contain a set of records that are sorted by each record's key. For example, when you have two ref records refs/heads/aaaaa and refs/heads/bbb, you have two ref records with these reference names as their respective keys, and refs/heads/aaaaa would come before refs/heads/bbb.
Furthermore, each section is divided into blocks of a fixed length. This block length is encoded in the header and serves two purposes:
- Given the start of the section as well as the block size, the reader implicitly knows where each of the blocks starts. This allows Git to easily seek into the middle of a section without reading preceding blocks, which enables binary searches over blocks to speed up the lookup of records.
- It ensures that the reader knows how much data to read from the disk at a time. Consequently, the block size is by default set to 4KiB, which is the most common sector size for hard disks. The maximum block size is 16MB.
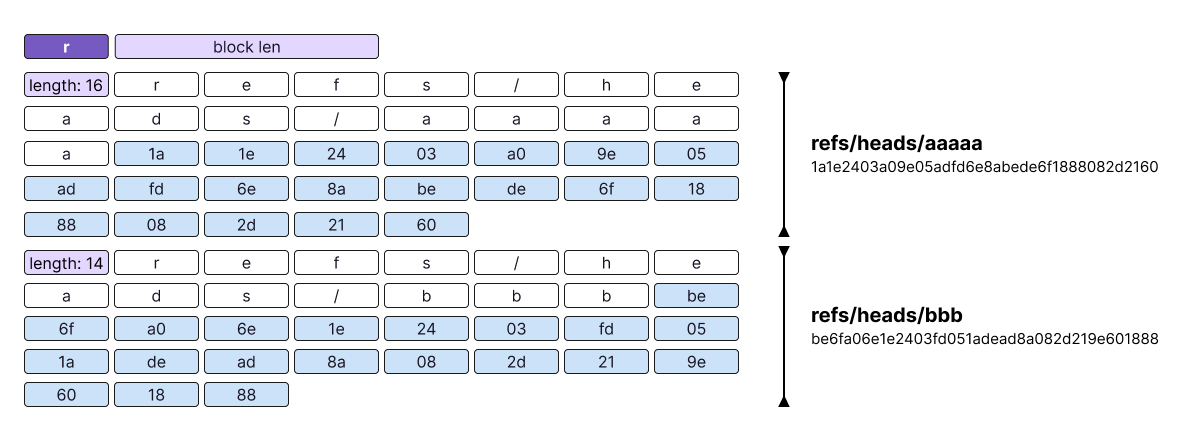
When we peek into, for example, a "ref" section, it looks roughly like the following graphic. Note how its records are ordered lexicographically inside the blocks, but also across the blocks.
Equipped with the current information, we can locate a record by using the following steps:
-
Perform a binary search over the blocks by looking at the keys of their respective first records, identifying the block that must contain our record.
-
Perform a linear search over the records in that block.
Both of these steps are still somewhat inefficient. If we have many blocks we may have to read logarithmically many of them in our binary search to find the desired one. And when blocks contain many records, we potentially have to read all of them during the linear search.
The "reftable" format has additional built-in mechanisms to address these performance concerns. We will touch on these over the next few sections.
Prefix compression
As you may have noticed, all of the record keys share the same prefix refs/. This is a common thing in Git:
- All branches start with refs/heads/.
- All tags start with refs/tags/.
Therefore, we expect that subsequent records will most likely share a significant prefix of their key. This is a good opportunity to save some precious disk space. Because we know that most keys will share a common prefix, it makes sense to optimize for this.
The optimization uses prefix compression. Every record encodes a prefix length that tells the reader how many bytes to reuse from the key of the preceding record. If we have two records, refs/heads/a and refs/heads/b, the latter can be encoded by specifying a prefix length of 11 and then only storing the suffix b. The reader will then take the first 11 bytes of refs/heads/a, which is refs/heads/, and append the suffix b to it.
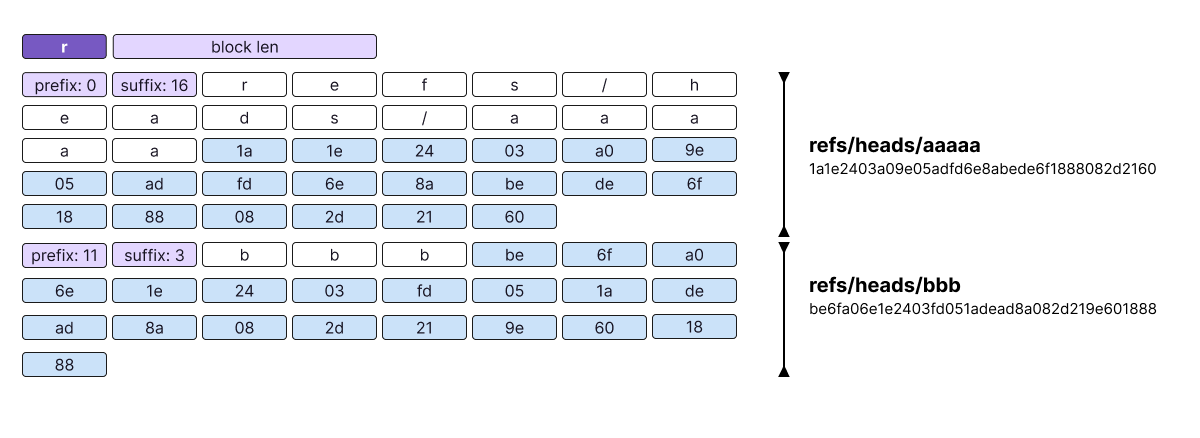
Restart points
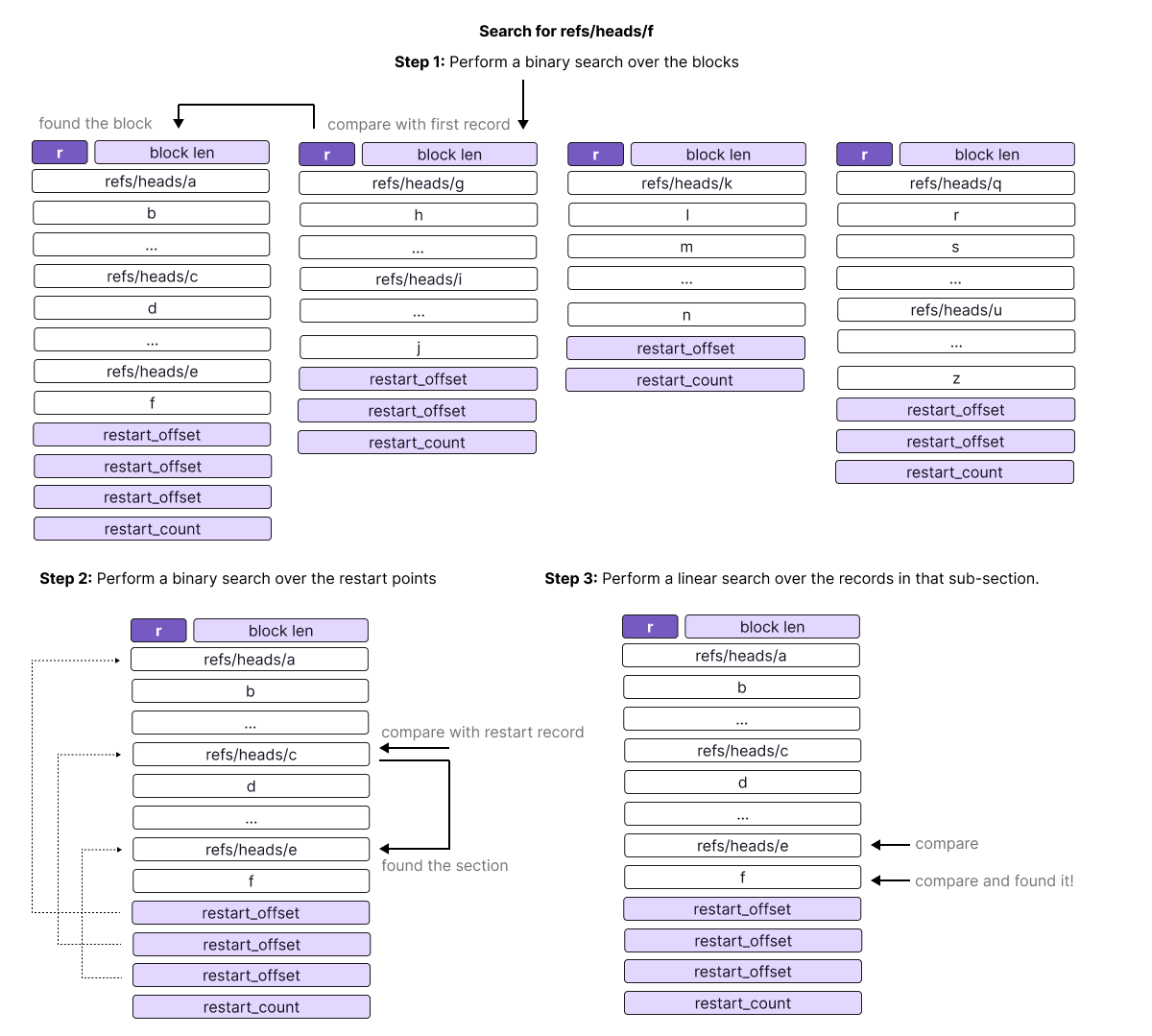
As explained earlier, the best way to search for a reference in a block with our current understanding of the "reftable" format is to do a linear search. This is because records do not have a fixed length, so it is impossible for us to tell where records would start without scanning through the block from the beginning. Also, even if records were of fixed length, we would not be able to seek into the middle of a block because the prefix compression also requires us to read preceding records.
Doing a linear search would be quite inefficient because blocks may contain hundreds or even thousands of records. To address this issue, the "reftable" format encodes so-called restart points into every block. Restart points are uncompressed records where the prefix compression is reset. Consequently, records at restart points always contain their full key and it becomes possible to directly seek to and read the record without having to read preceding records. These restart points are listed in the footer of each block.
Equipped with this information, we can avoid performing a linear search over the block. Instead, we can now do a binary search over the restart points where we search for the first restart point with a key larger than the sought-after key. From there, it follows that the desired record must be located in the section spanning from the preceding restart point to the identified one.
Thus, our initial procedure to look up a record (binary search for the block, linear search for the record) is now:
-
Perform a binary search over the blocks, identifying the block that must contain our record.
-
Perform a binary search over the restart points, identifying the sub-section of the block that must contain our record.
-
Perform a linear search over the records in that sub-section.
Indices
While the search for records inside a block is now reasonably efficient, it's still inefficient to locate the block itself. A binary search may be reasonably performant when you have a couple of blocks, but repositories with millions of references may have hundreds or even thousands of blocks. Without any additional data structure, this would cause logarithmically many disk seeks on average.
To avoid this, every section may be followed by an index section that provides an efficient way to look up a block. Each index record holds the following information:
- The location of the block that it is indexing.
- The key of the last record of the block that it is indexing.
With three or less blocks, a binary search will always require, at most, two disk reads to find the desired target block. This is the same number of reads we would have to do with an index: one to read the index itself and one to read the desired block. Consequently, indices are only written when they would actually save some reads, which is the case with four or more indexed blocks.
Now the question is: What happens when the index itself becomes so large that it spans over multiple blocks? You might have guessed it: We write another index that indexes the index. These multi-level indices really only become necessary once you have repositories with hundreds of thousands of references.
Equipped with these indices, we can now make the procedure to look up records even more efficient:
- Determine whether there is an index by looking at the footer of the table.
- If there is one, perform a binary search over the index to find the desired block. This block may point into an index block itself, in which case we need to repeat this step until we hit a record of the desired type.
- Otherwise, perform a binary search over the blocks as we did before.
- Perform a binary search over the restart points, identifying the sub-section of the block that must contain our record.
- Perform a linear search over the records in that sub-section.
Multiple tables
Up to this point, we have only discussed how to read a single table. But as the name tables.list indicates, you can actually have a list of tables in your "reftable" database.
Every time you update a reference in your repository, a new table is written and appended to tables.list. Thus, you will eventually end up with multiple tables:
$ tree .git/reftable/ .git/reftable/ ├── 0x000000000001-0x000000000007-8dcd8a77.ref ├── 0x000000000008-0x000000000008-30e0f6f6.ref └── tables.list $ cat .git/reftable/tables.list 0x000000000001-0x000000000007-8dcd8a77.ref 0x000000000008-0x000000000008-30e0f6f6.refReading the actual state of a repository requires us to merge these multiple tables into a single virtual table.
You might be wondering: If a table is written for each reference update and the same reference is updated multiple times, how does the "reftable" format know the most up-to-date value of a given reference? Intuitively, one could assume the value would be the one from the newest table containing the reference.
In fact, every single record has a so-called update index that encodes the "priority" of a record. For example, if two ref records with the same name exist, then the one with the higher update index overrides the one with the lower update index.
These update indices are visible in the file structure above. The long hex strings (for example 0x000000000001) are the update indices, where the left-hand side of the table name is the minimum update index contained in the table and the right-hand is the maximum update index.
Merging the tables then happens via a priority queue that is ordered by the key of the ref record as well as its update index. Assuming we want to scan through all ref records, we would:
- For every table, add its first record to the priority queue.
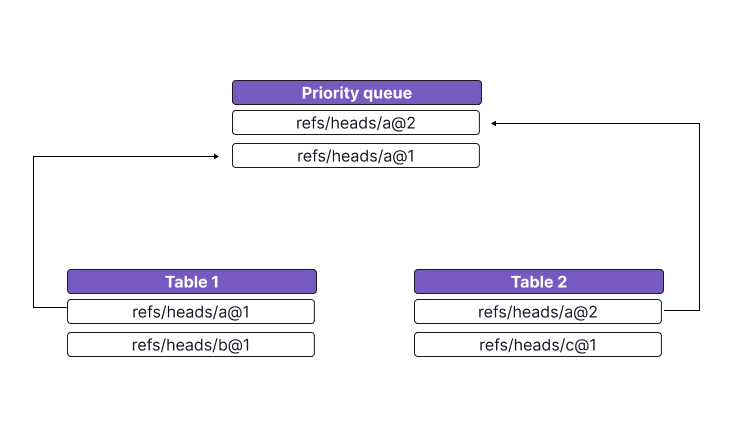
- Yield the head of the priority queue. Because the queue is ordered by update index, it must be the most up-to-date version. Add the next item from that table to the priority queue.
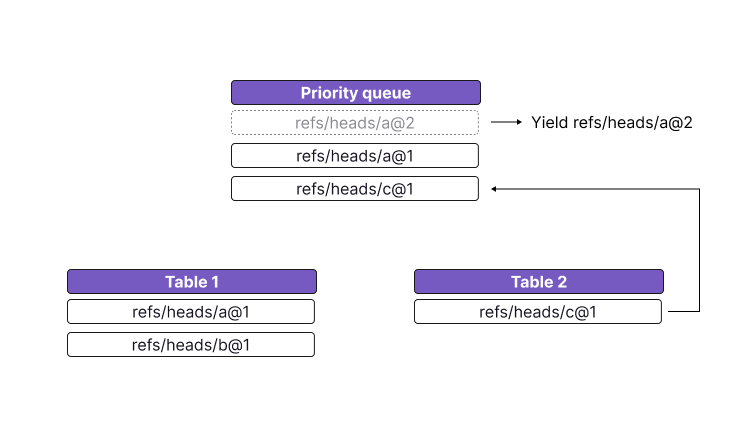
- Drop all records from the queue that have the same name. These records are shadowed, which means that they will not be shown. For each table for which we are dropping records, add the next record to the priority queue.
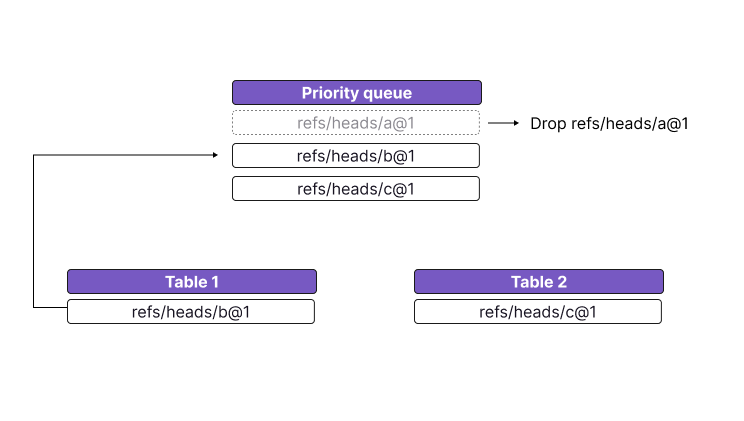
Now we can rinse and repeat to read records for other keys.
Tables may contain special "tombstone" records that mark a record as having been deleted. This allows us to delete records without having to rewrite all tables to not contain the record anymore.
Auto-compaction
While the idea behind the priority queue is simple enough, it would be rather inefficient to merge together hundreds or even only dozens of tables in this way. So while it is true that every update to your references appends a new table to your tables.list file, it is only part of the story.
The other part is auto-compaction: After a new table has been appended to the list of tables, the "reftable" backend checks whether some of the tables should be merged. This is done by using a simple heuristic: We check whether the list of tables forms a geometric sequence with the file sizes. Every table n must be at least twice as large as the next-most-recent table n + 1. If that geometric sequence is violated, the backend will compact tables so that the geometric sequence is restored.
Over time, this will lead to structures that look like the following:
$ du --apparent-size .git/reftable/* 429 .git/reftable/0x000000000001-0x00000000bd7c-d9819000.ref 101 .git/reftable/0x00000000bd7d-0x00000000c5ac-c34b88a4.ref 32 .git/reftable/0x00000000c5ad-0x00000000cc6c-60391f53.ref 8 .git/reftable/0x00000000cc6d-0x00000000cdc1-61c30db1.ref 3 .git/reftable/0x00000000cdc2-0x00000000ce67-d9b55a96.ref 1 .git/reftable/0x00000000ce68-0x00000000ce6b-44721696.ref 1 .git/reftable/tables.listNote how for every single table, the property size(n) > size(n+1) * 2 holds.
One of the consequences of auto-compaction is that the "reftable" backend maintains itself. We no longer have to run git pack-refs in a repository.
Want to learn more?
You should now have a good understanding of how the new "reftable" format works under the hood. If you want to dive even deeper into the format, you can refer to the technical documentation provided by the Git project.
Read our Git 2.45.0 recap to find out what else is in this version of Git.